-
Why AI Evaluations Need Statistical Rigor
AI evaluations often rely on single-run scores even though models, agents, and judges are inherently stochastic, making many reported differences unstable. This post surveys statistical tools—error bars, reliability measures, Bayesian models—that show and help manage this variance. Overall, it highlights how incorporating established statistical practices can make evaluations more trustworthy and informative.
-
Computer Use Survey - A Visual Survey of Computer Use Agents
In recent years, AI systems operating on the web and in computer environments have become a major topic of interest for both academia and industry. The goal of this blog is to provide an interesting and interactive survey of historical and recent works on computer use agents. We define key terms used in the literature, catalogue the expansive list of environments and datasets, discuss the evolution of the methodologies, and assess both today’s landscape and possible paths forward.
-
Wait, Do We Need to Wait? Revisiting Budget Forcing for Sequential Test-Time Scaling
This blog revisits budget forcing, a sequential test-time scaling technique for reasoning models by controlling when it continues thinking versus when it must answer. We evaluate how well the method transfers across model types, including non-reasoning models, and whether alternative keywords work. We provide practical guidelines for using the technique.
-
Visualizing LLM Latent Space Geometry Through Dimensionality Reduction
In this blog post, we extract, process, and visualize latent state geometries in Transformer-based language models through dimensionality reduction to build a better intuition of their internal dynamics. We demonstrate experiments with GPT-2 and LLaMa models, uncovering interesting geometric patterns in their latent spaces. Notably, we identify a clear separation between attention and MLP component outputs across intermediate layers, a pattern not documented in prior work to our knowledge.
-
What (and What Not) are Calibrated Probabilities Actually Useful for?
This blogpost clarifies the practical usefulness of having a model with calibrated probabilities, something that is not often clearly stated in the calibration literature. We show that a calibrated model can be relied on to estimate average loss/reward, however, good calibration does not mean that a model is useful for per-sample decision making.
-
UnigramLM - An Attempt at Writing the Missing Manual
This post is my attempt to write down the UnigramLM tokenization algorithm cleanly and explicitly because no such derivation appears to exist and I think understanding the theory behind the method could help us improve it. I'll formalize the generative model around which the algorithm is based, derive the EM updates, explain why pruning is needed (and how it's done), and point out the spots where the practical implementation defined by the SentencePiece library diverges from the pretty mathematical models. I hope this post provides a new lens through which to look at the UnigramLM tokenization algorithm while pointing out some interesting potential extensions/revisions to the current implementation.
-
Trade-offs in LLM Compute for Reasoning-Intensive Information Retrieval
The BRIGHT benchmark (ICLR 2025 Spotlight) revealed that reasoning-intensive information retrieval requires LLM-augmented pipelines, but this raises a critical resource allocation question: where should computational budget be invested for maximum effectiveness? We conduct a systematic study on BRIGHT using the Gemini 2.5 model family, evaluating trade-offs across model strength, inference-time thinking depth, and reranking depth. Our controlled experiments quantify the marginal gains of allocating compute to query expansion versus reranking, providing practical guidance for optimizing LLM-based retrieval systems on reasoning-intensive tasks.
-
Tracing the Principles Behind Modern Diffusion Models
Diffusion models can feel like a jungle of acronyms, but the core idea is simple: start from noise and gradually move a cloud of samples until it looks like real data. This post gives an intuition-first tour showing that DDPMs, score-based models, and flow matching are the same recipe with different prediction targets, all rooted in the change-of-variable rule from calculus and powered by one shared “conditional trick” that turns learning into supervised regression. Finally, we zoom out to the speed problem and show how flow map models aim to replace many tiny denoising steps with a few big, accurate jumps toward real-time generation.
-
The Evolution of FlashAttention
We present a mathematical & technical overview of FlashAttention and its evolution across versions 1 to 4. We explain why IO-aware design became central to scalable transformers and how these kernels shape modern long-context LLMs as memory patterns and hardware limits shift. We then describe the changes across versions with Triton examples and place these kernels in the context of recent work on efficient attention. We close by outlining principles that can guide the next generation of attention algorithms.
-
Artistic Style and the Play of Neural Style Representations
How do neural networks percieve the complex human construct of artistic style? We explore the dynamic interplay between diverse machine representations of style and style definitions. We reveal a profound divergence where models often reject established historical narratives in favour of their own perceptual truths.
-
Where's the Chicken? Unpacking Spatial Awareness in Vision-Language Models
Modern vision-language models (VLMs) have achieved impressive success in recognizing and describing visual content, yet they continue to struggle with understanding spatial relationships. The limitation persists even with massive data and model scaling, suggesting that the root of the problem lies in the architecture and training objective rather than data alone. This post examines the underlying causes and discusses why recent proposed fixes, while promising, remain insufficient to achieve robust spatial reasoning.
-
Don't Look Up (Every Token): Escaping Quadratic Complexity via Geometric Patterns and Algorithms
Large Language Models (LLMs) have brought about a significant change in the field of artificial intelligence, where they have transitioned in scope from being specialized research tools to common resources that drive the next generation of software. With increasing model parameters and training data, LLMs demonstrate new abilities in reasoning, code generation, and solving complex problems that were once considered unattainable. However, scaling these models effectively for long-context applications uniquely poses a challenge. This is primarily due to the inherent limitations of the self-attention mechanism, which has quadratic time complexity. This quadratic bottleneck hinders applications for long documents, high-resolution images, and large codebases, among others. However, what is interesting to observe is that effectively only a few parameters are used in token computation, and most calculations are sparse. Hence, sparsity emerges as an effective solution to this problem. Rather than relying on the entire attention matrix, one can utilize an approximate or sparse version of attention to achieve almost the same results much faster. The backbone of this approach is the idea that tokens do not require the entire context; they only need local context, and thus, most of the computation carried out is wasteful. In this blog, we analyze the types of attention patterns that emerge and how to use them to our advantage for faster and efficient LLMs.
-
Using Graph Neural Networks in Reinforcement Learning: A Practical Guide
Graph Neural Networks (GNNs) have achieved excellent results for modelling relational data in many supervised learning domains. However, much fewer works have explored their potential in Reinforcement Learning (RL) despite the ubiquity of practical problems defined over graphs. In this blog post, we discuss how GNNs can be effectively integrated in Deep RL frameworks, covering crucial design decisions and practical implementation concerns. In doing so, we hope to facilitate unlocking new capabilities for RL agents to reason in graph-structured environments with dynamic action spaces and varying input sizes.
-
Revisiting The NetHack Learning Environment
The NetHack Learning Environment (NLE) was proposed as a challenging benchmark to test an agents abilities to perform complex reasoning over long time horizons in a stochastic, partially-observed, procedurally generated setting. To date, no approach, including those based on reinforcement learning, using large pretrained models, using handcoded symbolic agents, imitating expert trajectories or any hybrid method has achieved significant progress towards completing the game. We take a deeper look into the mechanics and interface of the NLE and show that much of the complexity of NetHack is inaccessible due to constraints on the observation and action spaces. We propose a series of modifications and show that they meaningfully improve performance on the NLE.
-
Rethinking the Diffusion Model from a Langevin Perspective
Diffusion models are often introduced from multiple perspectives—such as VAEs, score matching, or flow matching—accompanied by dense and technically demanding mathematics that can be difficult for beginners to grasp. One classic question is How does the reverse process invert the forward process to generate data from pure noise? This article systematically organizes the diffusion model from a fresh Langevin perspective, offering a simpler, clearer, and more intuitive answer. We also address the following questions 1. How can ODE-based and SDE-based diffusion models be unified under a single framework? 2. Why are diffusion models theoretically superior to ordinary VAEs? 3. Why is flow matching not fundamentally simpler than denoising or score matching, but equivalent under maximum-likelihood? We demonstrate that the Langevin Perspective offers clear and straightforward answers to these questions, providing pedagogical value for both learners and experienced researchers seeking deeper intuition.
-
Dynamic Parameter Reuse Augments Reasoning via Latent Chain of Thought
Standard language models often rely on massive parameter counts for their performance, utilizing each parameter only once per inference pass. This prompts consideration of recurrent structures, where models reuse parameters across sequential time, depth, or training progression to achieve improved performance and reduced training cost. We draw connections in the landscape of parameter reuse, from growing models via stacking to recurrent looping, and postulate that these architectural priors act as a form of Latent Chain of Thought (LCoT), allowing models to reason in a continuous state space. By shifting towards deeper and dynamic computation, grown and recurrent architectures offer a path toward improved reasoning in compact networks, ascending beyond scaling laws of standard architectures.
-
Probabilistic Circuits for Uncertainty Quantification
Deep learning models struggle with epistemic uncertainty quantification, often exhibiting blind confidence on out-of-distribution data. This work reviews Probabilistic Circuits (PCs) as a versatile framework for rigorous, tractable reasoning. PCs model the joint probability distribution and by enforcing structural constraints, specifically smoothness, decomposability, and determinism, they allow for the exact computation of marginals, conditionals, and moments in polynomial time without retraining. We discuss the suitability of PCs for Uncertainty Quantification, describing their advantages and highlighting their potential for tractable UQ in high-dimensional problems.
-
Extracting Model Precision from 20 Logprobs
We demonstrate that the internal floating-point precision of language models can be inferred from API-exposed logprobs.
-
Effect of Parallel Environments and Rollout Steps in PPO
This blog post explores batch size in PPO-what happens when we increase the number of parallel environments versus the number of rollout steps, while keeping the total samples per update fixed. We discuss how this affects bias and variance in gradient estimation.
-
Faster SVD via Accelerated Newton-Schulz Iteration
Traditional SVD algorithms rely heavily on QR factorizations, which scale poorly on GPUs. We show how the recently proposed Chebyshev-Accelerated Newton-Schulz (CANS) iteration can replace them and produce an SVD routine that is faster across a range of matrix types and precisions.
-
Performative Prediction made practical
Performative Prediction studies settings where deploying a model induces a distribution shift in the data with the aim of building robust and good-performing models under these post-deployment effects. Most existing work in this area is theoretical and relies on strict assumptions to converge to those models, making the resulting techniques difficult to apply in practice and limiting their accessibility to the broader Machine Learning (ML) community. In this blog post, we use visualization techniques 1) to provide an intuitive explanation of Performative Prediction and 2) to extract practical insights for studying convergence when theoretical assumptions do not hold.
-
Language as a Window Into the Mind: How NLP and LLMs Advance Human Sciences
Can NLP predict heroin-addiction outcomes, uncover suicide risk, or simulate (and even influence) brain activity? Could LLMs one day contribute to research worthy of a Nobel Prize for advancing our understanding of human behavior? And what role do NLP scientists play in shaping that possibility? This post explores these questions, arguing that language technologies are not just tools that support scientific work (like literature search agents, writing tools, or coding assistants), but that by treating language as a window into the human mind, NLP and LLMs can actively help researchers uncover mechanisms of human behavior, cognition, and brain function.
-
Model Misspecification in Simulation-Based Inference - Recent Advances and Open Challenges
Model misspecification is a critical challenge in simulation-based inference (SBI), particularly in neural SBI methods that use simulated data to train flexible neural density estimators. These methods typically assume that simulators faithfully represent the true data-generating process, an assumption that is often violated in practice. Resulting discrepancies can make observed data effectively out-of-distribution relative to the simulations, leading to biased posterior distributions and misleading uncertainty quantification. This post reviews recent work on model misspecification in neural SBI, covering formal definitions, methods for detection and mitigation, and their underlying assumptions. It also discusses practical implications for SBI workflows and outlines open challenges for developing robust SBI methods that remain reliable in realistic, imperfectly specified applications.
-
Evaluating Machine-Learned Inter-Atomic Potentials for a Practical Simulation Workflow
MLIPs are a promising paradigm in atomistic simulation, potentially offering the accuracy of ab-initio methods at the speed of empirical potentials. In this blog post, we give an overview of recent MLIP architectures, followed by an evaluation on a practical CO2 adsorption simulation. We find that as of today these models, though promising, are far from plug-and-play, requiring significant engineering effort to operate within established simulation frameworks, while also failing to produce physically consistent results.
-
Is the evidence in 'Language Models Learn to Mislead Humans via RLHF' valid?
Language Models Learn to Mislead Humans via RLHF (published at ICLR 2025) argues that RLHF can unintentionally train models to mislead humans – a phenomenon termed Unintentional-SOPHISTRY. However, our review of the paper's code and experiments suggests that a significant portion of their empirical findings may be due largely to major bugs that make the RLHF setup both unrealistic and highly prone to reward hacking. In addition to high-level claims, we correct these issues for one of their experiments, and fail to find evidence that supports the original paper's claims.
-
Misalignment Patterns and RL Failure Modes in Frontier LLMs
With the rapid ability grokking of frontier Large Models (LMs), there is growing attention and research focus on aligning them with human values and intent via large scale reinforcement learning and other techniques. However, as LMs are getting stronger and more agentic, their misalignment and deceptive behaviors are also emerging and becoming increasingly difficult for humans to pre-detect and keep track of. This blog post discusses current misalignment patterns, deceptive behaviors, RL failure modes, and emergent traits in modern large models to further AI safety discussions and advance the development of mitigation strategies for LM misbehaviors.
-
Learning to Maximize Rewards via Reaching Goals
Goal-conditioned reinforcement learning learns to reach goals instead of optimizing hand-crafted rewards. Despite its popularity, the community often categorizes goal-conditioned reinforcement learning as a special case of reinforcement learning. In this post, we aim to build a direct conversion from any reward-maximization reinforcement learning problem to a goal-conditioned reinforcement learning problem, and to draw connections with the stochastic shortest path framework. Our conversion provides a new perspective on the reinforcement learning problem: maximizing rewards is equivalent to reaching some goals.
-
Loneliness as a Case Study for Social Reward Misalignment
The goal of this blogpost is to use loneliness as a clean case study of social proxy-reward misalignment in RL. We introduce a minimal homeostatic environment with loneliness drift and accumulated harm, and show that engagement-optimized agents learn short-term “social snack” policies that reduce the error signal without improving the underlying social state. This simple testbed highlights why reward inference or well-being objectives may be a better foundation than engagement proxies for socially aligned AI.
-
From REINFORCE to Dr. GRPO: A Unified Perspective on LLM Post-Training
Recently, many reinforcement learning (RL) algorithms have been applied to improve the post-training of large language models (LLMs). In this article, we aim to provide a unified perspective on the objectives of these RL algorithms, exploring how they relate to each other through the Policy Gradient Theorem — the fundamental theorem of policy gradient methods.
-
The human knowledge loophole in the 'bitter lesson' for LLMs
Are LLMs a proof that the 'bitter lesson' holds for NLP? Perhaps the opposite is true: they work due to the scale of human data, and not just computation.
-
The Layered Ontology of Models, Resolving the Epistemological Crisis of AI
I propose a five-layer model framework and discuss the concepts of Meaning and Truth in the era of large models through two thought experiments.
-
JustRL: Scaling a 1.5B LLM with a Simple RL Recipe
Training small reasoning models with RL has become a race toward complexity, using multi-stage pipelines, dynamic schedules, and curriculum learning. We ask whether this complexity necessary? We show that JustRL, a simple recipe with fixed hyperparameters, achieves state-of-the-art performance on two different 1.5B base models (54.5% and 64.3% across 9 math benchmarks) while using 2× less compute than sophisticated approaches. The same hyperparameters transfer across both models without tuning, and training remains stable over thousands of steps without intervention. This suggests the field may be adding complexity to solve problems that disappear with a stable, scaled-up baseline.
-
How To Open the Black Box: Modern Models for Mechanistic Interpretability
Understanding how transformers represent and transform internal features is a core challenge in mechanistic interpretability. Traditional tools like attention maps and probing reveal only partial structure, often blurred by polysemanticity and superposition. More principled alternatives work by recovering interpretable structure directly from activations: Sparse Autoencoders extract sparse, disentangled features from the residual stream; Semi-Nonnegative Matrix Factorization decomposes MLP activations into neuron-grounded building blocks; Cross-Layer Transcoders trace how these features propagate and transform across depth. Together, they form a coherent, feature-centric framework for understanding what transformers learn and how they compute.
-
Heuristic-Based Ideation for Guiding LLMs Toward Structured Creativity
Large Language Models (LLMs) hold immense promise for accelerating scientific discovery, yet current LLM-based ideation methods often rely on ad-hoc strategies rather than systematic frameworks. This blog introduces Ideation Heuristics, a systematic approach that formalizes 20 heuristics that structure how researchers generate new ideas. We show that researchers across disciplines find these heuristics highly useful, and we demonstrate how they can be operationalized through skills.
-
In-context learning of representations can be explained by induction circuits
Park et al., 2025 find that when large language models process random walks on a graph in-context, the geometry of their token representations comes to mirror the graph's connectivity structure. This suggests a two-step mechanism: the model first reshapes its representations to reflect the graph structure, then operates over them to predict valid next steps. We offer a simpler mechanistic explanation. The in-context graph tracing task can be solved by induction circuits, which implement a simple rule: if token B followed token A earlier in the sequence, predict B the next time A appears. Since consecutive tokens in a random walk are always graph neighbors, this rule naturally produces valid steps. Ablating the attention heads that comprise induction circuits substantially degrades task performance, compared to ablating random heads. As for the geometric structure of representations, we propose that induction circuits can account for this too: their previous-token heads mix each token's representation with that of its predecessor, always a graph neighbor in a random walk. We show that a single round of such 'neighbor mixing' applied to random embeddings is sufficient to recreate the graph-like PCA structure. These results suggest that the observed representation geometry is a byproduct of how the model solves the task, not the means by which it does so.
-
Diffusion as Infinite Hierarchical VAEs - Do Diffusion Models Generalize Better than Deep VAEs?
This blogpost unifies Diffusion Models and Variational Autoencoders. We demonstrate that DPMs are mathematically equivalent to Hierarchical VAEs (HVAEs) in the limit of infinite depth. By analyzing this architectural link, we explain why diffusion models avoid the posterior collapse that plagues deep VAEs and identify the sweet spot for generalization where these models perform best.
-
Ready For General Agents? Let's Test It.
General-purpose agents are emerging, promising seamless deployment across domains. However, we currently do not measure their adaptability to diverse, unseen settings—a core requirement for true generality. We outline the key challenges and chart a path toward a unified evaluation framework designed to guide the development of general agents.
-
Divide, Conquer, and Standardize - A Recursive Architecture for Multi-Agent Systems (MAS)
The scalability and robustness of current Multi-Agent Systems (MAS) are severely constrained by the heterogeneity of communication interfaces and a reliance on fragile ad-hoc integrations. We introduce FRACTAL-MAS, a recursive architecture that standardizes orchestration through the convergence of MCP and A2A protocols, integrating a unified control loop with procedural memory grounded in Case-Based Reasoning (CBR). This design allows for continuous adaptation without fine-tuning and enables a seamless transition from rigid hierarchical structures to decentralized networks, providing a reference architecture for the robust and scalable construction of MAS.
-
Flow Where You Want
This tutorial demonstrates how to add inference-time controls to pretrained flow-based generative models operating in latent space. Using an unconditional MNIST flow model, we apply classifier guidance and inpainting by adding velocity corrections during sampling. We also explore PnP-Flow, which satisfies constraints through iterative projection rather than velocity correction.
-
From Trajectories to Operators — A Unified Flow Map Perspective on Generative Modeling
In this post, we reframe continuous-time generative modeling from integrating trajectories to learning two-time operators (flow maps). This operator view unifies diffusion, flow matching, and consistency models, and suggests a practical diagnostic — semigroup-consistent jumps yield both step-robust generation and low compositional drift. We derive Eulerian/Lagrangian distillation objectives and use inpainting experiments to show why semigroup-consistent jumps can be both step-robust and composition-stable.
-
Understanding and Fixing Bottlenecks in State Space Models: What Recency and Over-Smoothing Tell Us
This work analyzes how recency bias and hidden-state over-smoothing emerge in modern State Space Models, revealing the bottlenecks that limit their ability to capture long-range dependencies.
-
The effect of feature resolution on embedding dimension
High-dimensional data can be compressed into lower-dimensional embeddings while retaining a relatively large amount of relevant information, a phenomenon which, despite its widespread use, we struggle to fully explain. In this post, we use a common property of datasets - a limit on the number of features per data point - to show how a slight uniform dependence between features can be exploited to reduce the required dimensions by at least a third, while sacrificing no information about the features. To do so, we introduce the concepts of dataset resolution and feature composition of a dataset, and analyse how a set of orderings of the dataset affects the types of partitions we can create of the dataset.
-
AI Fundamentals: Valuing AI Agents & Data Assets
Large Language Model (LLM) agents now read the world through managed-context pipelines, write to it via tool-calling APIs, and continuously re-wire themselves with fresh experience. Stakeholders therefore need a Generally Accepted Accounting Principles (GAAP) compatible method to price both (i) the agent's labour-like output and (ii) the data traces that fuel learning. We formalise a single unifying metric - agent Economic Value (AEV)- and demonstrate that these metrics are measurable today. We then extend the template to reinforcement-learning regimes in which grounded rewards equal cash flows. Lastly, we propose a financial settlement layer, which transforms the agent from a passive software user into an active economic participant.
-
dLLM - Rethinking Generation Beyond Autoregressive Models
Diffusion large language models (dLLMs) provide an alternative to autoregressive Transformers, supporting parallel token generation and flexible infilling. They excel in structured, long-horizon, or data-constrained settings, though challenges remain with output length, denoising, and blockwise generation. Hybrid approaches combining diffusion for reasoning and autoregressive for generation show promise.
-
Dissecting Non-Determinism in Large Language Models
The Large Language Models (LLMs) evolve into the backbone of complex decision-making systems, their inherent non-deterministic nature poses a significant threat to the validity of experimental results. This blog explores the impact of stochasticity, prompt brittleness, and LLM-as-a-Judge during both response generation and evaluation. We conclude that understanding these dynamics is essential to prevent misleading conclusions, advocating for consistency oriented practices that treat non-determinism as a critical variable in rigorous experimentation.
-
Navigating the Manifold — A Geometric Perspective on Diffusion-Based Inverse Problems
This blogpost develops a geometric and probabilistic lens on diffusion priors for inverse problems. We show that a wide range of methods mostly instantiate two operator-splitting paradigms, i.e., posterior-guided sampling and clean-space local-MAP optimization. Through manifold diagrams, Tweedie-based animations, and step-by-step derivations, we explain how these paradigms decouple a pretrained diffusion prior from measurement physics, clarify when they approximate full posterior sampling versus MAP estimation, and distill practical design rules for building robust diffusion-based inverse solvers.
-
From U-Nets to DiTs: The Architectural Evolution of Text-to-Image Diffusion Models (2021–2025)
A comprehensive analysis of how diffusion model architectures evolved from U-Net backbones to Diffusion Transformers, transforming text-to-image generation capabilities.
-
Destruction is a General Strategy to Learn Generation; Diffusion's Strength is to Take it Seriously; Exploration is the Future
I present diffusion models as part of a family of machine learning techniques that withhold information from a model’s input and train it to guess the withheld information. I argue that diffusion's destroying approach to withholding is more flexible than typical hand-crafted information withholding techniques, providing a rich training playground that could be advantageous in some settings, notably data-scarce ones. I then address subtle issues that may arise when porting reinforcement learning techniques to the diffusion context, and wonder how such exploration problems could be addressed in more diffusion-native ways. I do not have definitive answers, but I do point my fingers in directions I deem interesting. A tutorial follows this thesis, expanding on the destroy-then-generate perspective. A novel kind of probabilistic graphical models is introduced to facilitate the tutorial's exposition.
-
Content Promotion as a Strategic Game: How to Design Agentic Publishers for the Evolving Search Ecosystem in the GenAI Era?
With the rise of LLMs, publishers now operate in a dual world where traditional search and chat-like systems coexist. We propose a unified, game-theoretic view of this environment and highlight different tools, such as Multi-Agent Reinforcement Learning, that support the development of competitive content-optimization agents.
-
Defining and quantifying compositional structure
Compositionality is thought to be crucial in human cognition and AI, but we lack a scientific understanding of what it is. What kind of data is compositionally structured? Can we mathematically quantify the amount and character of compositional structure? This blog post introduces a novel approach for doing so, building off of existing tools from algorithmic information theory that formalize notions of complexity and structure. The mathematical definition of compositionality that we'll come to is rigorous, precise, and general, and the hope is that it can inspire novel research directions in AI for uncovering compositional structure in natural data.
-
ChunkTabPFN: Training-free Long Context
Tabular foundation models such as TabPFN are limited in practice by the memory cost of attention, which grows quadratically with the number of samples and features. While efficient attention backends alleviate this in principle, CUDA grid limits and hardware compatibility gaps prevent their direct application at the scale of real-world tabular datasets. We introduce Chunked TabPFN, an exact tiling strategy that removes these implementation bottlenecks without retraining or approximation, extending TabPFN to 100K+ rows on a single GPU. On the long-context slice of TabArena, we find that — contrary to earlier reports — TabPFN's performance continues to improve with larger contexts, suggesting that the prior bottleneck was implementation-level memory, not model-level capacity.
-
Budget Alignment: Making Models Reason in the User's Language
We explore a two step multilingual alignment recipe for large language models to keep reasoning and answers in the user language while preserving accuracy.
-
The 99% Success Paradox: When Near-Perfect Retrieval Equals Random Selection
For most of the history of information retrieval (IR), search results were designed for human consumers who could scan, filter, and discard irrelevant information on their own. This shaped retrieval systems to optimize for finding and ranking more relevant documents, but not keeping results clean and minimal, as the human was the final filter. However, LLMs have changed that by lacking this filtering ability. To address this, we introduce Bits-over-Random (BoR), a chance-corrected measure of retrieval selectivity that reveals when high success rates mask random-level performance.
-
Square Peg, Round Hole: Plugging Non-Sequential Data into Sequential Language Models
Autoregressive (AR) models are central to modern generative AI systems, yet their need for an ordered sequence of tokens clashes with modalities that lack an obvious ordering, such as images, graphs, and point clouds. Despite this mismatch, AR models are widely applied beyond language owing to their scalability and controllability. In this post, we articulate exactly what the problem is, and how it can be solved. In short, there are two broad classes of techniques for applying AR models to non-sequential data: selecting a generation order given some fixed tokenization scheme, and redesigning the tokenization itself to simplify next-token prediction. Yet these methods face tradeoffs, particularly between compression (how many bits are used to represent the input) and autoregressive "modelability" (how easy it is to model each next-token conditional distribution in the chosen order). We predict that as data-hungry AI pipelines require new data modalities to train integrated, multi-modal models, these considerations will only grow more crucial. By drawing these connections, we aim to motivate future work on tokenizations tailored to the needs of autoregressive models for arbitrary datatypes.
-
An Overview of Subliminal Learning
In this blog post we survey the current state of subliminal learning research. We conclude by discussing the gaps in the literature which would take these techniques from research interests to potential real world concerns.
-
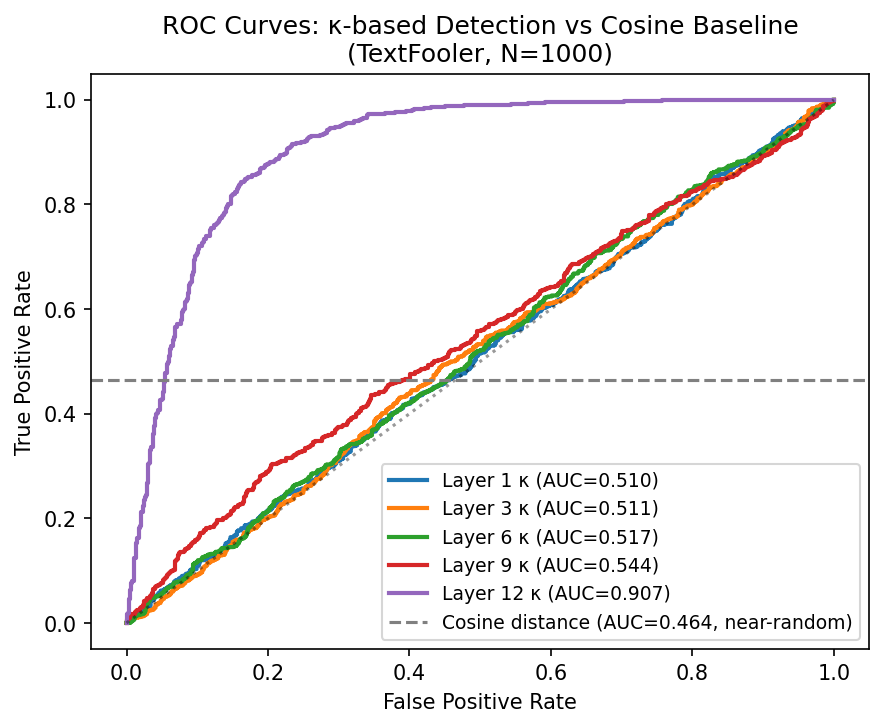
The Adversarial Conditioning Paradox: How Fine-Tuning Creates a Geometric Signature That Attacks Unknowingly Exploit
Adversarial attacks optimized purely against the softmax output reliably land in geometrically ill-conditioned regions at Layer 12 of fine-tuned BERT — a signature that does not exist before task training. We validate this finding across three attack families (TextFooler, PWWS, DeepWordBug) at N=1,000 each.