Faster SVD via Accelerated Newton-Schulz Iteration
Traditional SVD algorithms rely heavily on QR factorizations, which scale poorly on GPUs. We show how the recently proposed Chebyshev-Accelerated Newton-Schulz (CANS) iteration can replace them and produce an SVD routine that is faster across a range of matrix types and precisions.
(* denotes equal contribution)
In recent years, the polar decomposition has attracted considerable attention, with the Muon optimizer
In this blog post, we show that these ideas can be used to accelerate the computation of the singular value decomposition (SVD) via the polar decomposition on GPUs, yielding speedups of up to 2× compared with existing implementations.
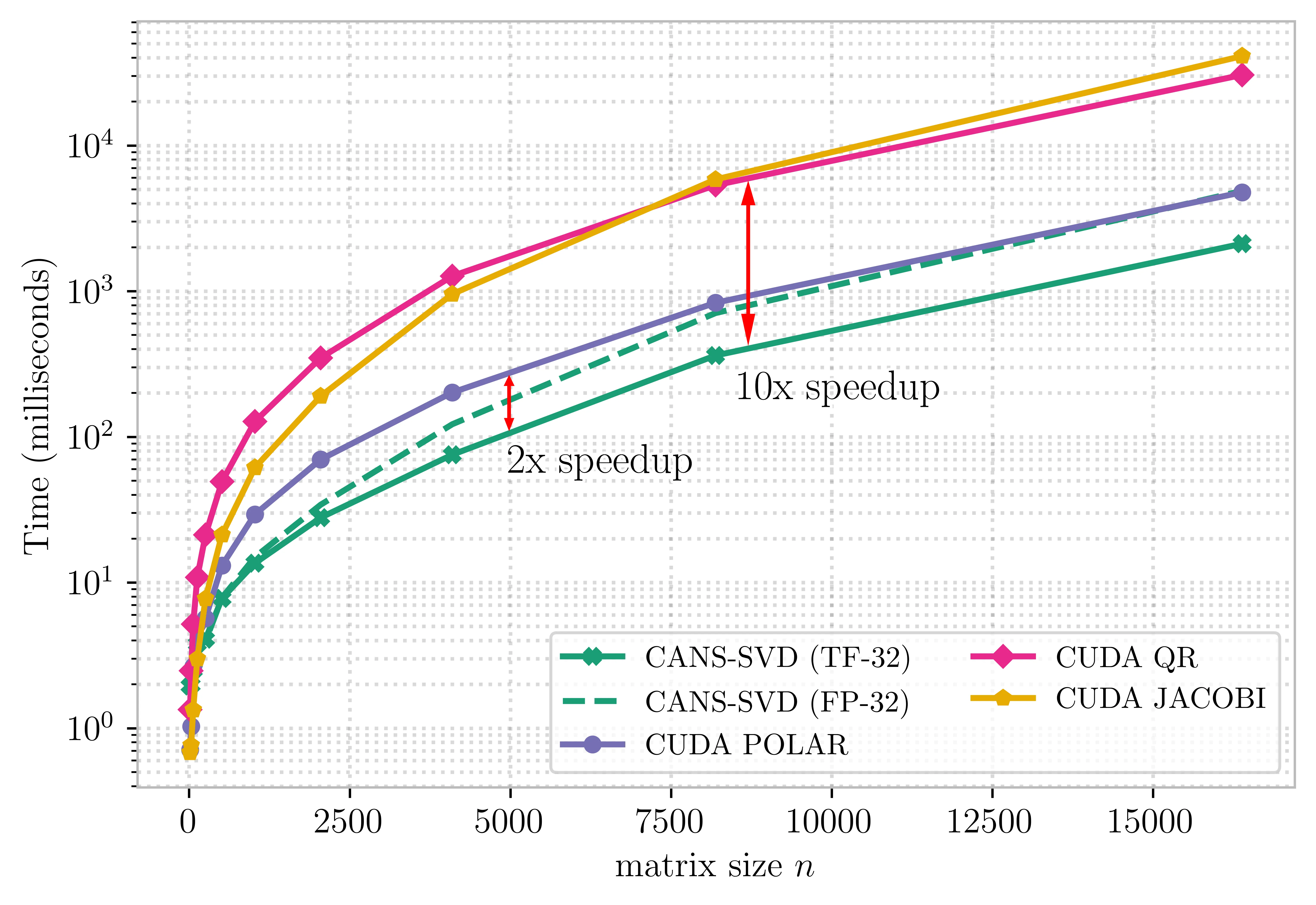
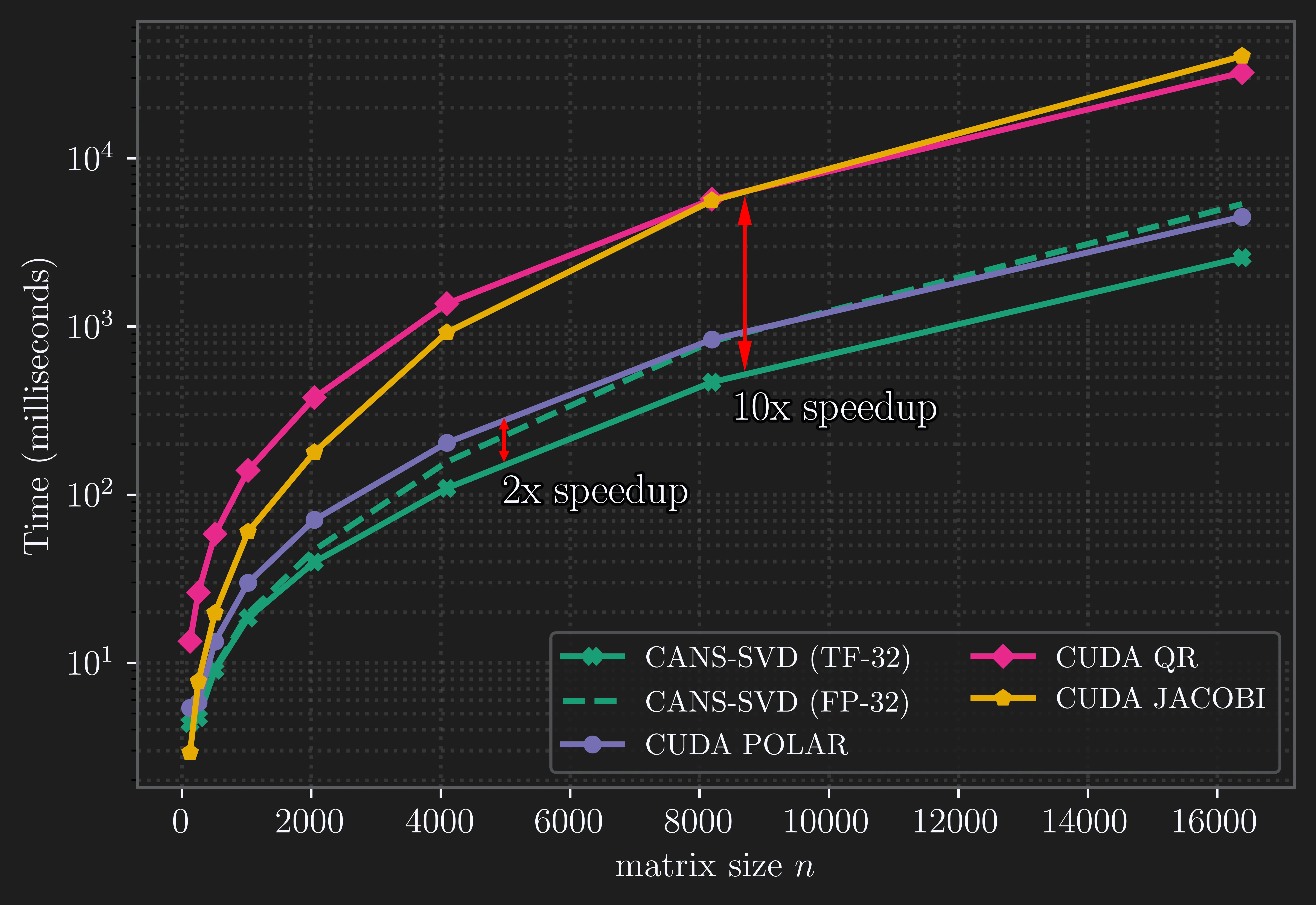
Since the CANS iteration relies fully on matrix multiplications, it is allowed to use the lower-precision TensorFloat-32 format to speed up computation. Consequently, CANS-SVD can be executed in two modes:
- Full FP-32 precision for a more accurate decomposition.
- TF-32 precision for a faster but less accurate result.
Other SVD implementations typically do not offer this level of precision flexibility.
Algorithm
Our method builds on the approach of computing the SVD via polar decomposition proposed in
def cans_svd(A: matrix, eps: float = 1e-5):
_A = cans_preprocessing(A) # preprocess matrix A
W = ns_based_iteration(_A) # compute the polar factor of A
H = W.T @ A # obtain the H - symmetric matrix
V, S = eigh(H) # eigendecomposition of symmetric matrix
U = W @ V
if any(abs(norm(U, axis=0) - 1) > eps):
U, _ = qr(U) # compute QR of U to fix orthogonality
# we consider QR with non-negative values on the R diagonal
return U, S, V.T
What is SVD?
For a matrix $A \in \mathbb{R}^{m \times n}$, the singular value decomposition is defined as
\[A = U \Sigma V^{\top},\]where $U \in \mathbb{R}^{m \times m}$ and $V \in \mathbb{R}^{n \times n}$ are orthogonal matrices, and $\Sigma \in \mathbb{R}^{m \times n}$ is a diagonal matrix whose diagonal entries are the non-negative singular values $\sigma_1 \ge \sigma_2 \ge \dots \ge \sigma_{\min(m, n)} \ge 0$.
What is polar decomposition?
Any matrix $A \in \mathbb{R}^{m \times n}$ with $m \ge n$ admits a polar decomposition
\[A = WH,\]where $W \in \mathbb{R}^{m \times n}$ has orthonormal columns and $H \in \mathbb{R}^{n \times n}$ is symmetric positive semidefinite. Remarkably, the polar factor $W$ is the closest matrix with orthonormal columns to $A$ with respect to Frobenius norm.
Here, cans_preprocessing refers to the preprocessing method introduced in ns_based_iteration refers to iteration based on the Newton-Schulz method, which efficiently computes the polar factor eigh and qr steps are typically faster
Experiments
We compare our algorithm with standard GPU-based SVD implementations from NVIDIA’s cuSOLVER library and observe the following results:
- On the NVIDIA B200 GPU, the TF-32 variant of CANS-SVD achieves up to a 2× speedup over the CUDA Polar-based SVD and up to a 10× speedup over the CUDA QR- and Jacobi-based SVD.
- The CUDA Polar-based SVD implementation (
driver=svdp) exhibits numerical instability on ill-conditioned or singular matrices, limiting its practical applicability. - The ability to use TF-32 precision is a unique advantage of CANS-SVD, whereas cuSOLVER algorithms rely on more complex procedures (such as QR and Givens rotations) that can only be computed in FP-32.
- The FP-32 variant of CANS-SVD consistently provides high accuracy across all test scenarios, while the TF-32 variant maintains a similar orthogonality error but exhibits higher reconstruction error. This gives rise to a trade-off between accuracy and precision.
Varying Condition Number
To assess numerical stability, we generate random matrices $A \in \mathbb{R}^{4096 \times 4096}$ with varying condition numbers $\kappa_2 = ||A||_2 ||A^{-1}||_2$, where $||\cdot||_2$ is the spectral norm (see Appendix). The condition number is one of the key factors influencing stability and accuracy of numerical linear algebra algorithms
Table 1. Relative Reconstruction error for different condition number values
| Method | $\kappa_2=1.1$ | $\kappa_2=10$ | $\kappa_2=10^2$ | $\kappa_2=10^4$ |
|---|---|---|---|---|
| CUDA POLAR | $5.4\cdot10^{-6}$ | $4.3\cdot10^{-6}$ | $5.4\cdot10^{-6}$ | $7.6\cdot10$ |
| CUDA QR | $1.8\cdot10^{-5}$ | $1.6\cdot10^{-5}$ | $2.7\cdot10^{-5}$ | $1.7\cdot10^{-5}$ |
| CUDA JACOBI | $1.9\cdot10^{-3}$ | $9.8\cdot10^{-4}$ | $8.4\cdot10^{-4}$ | $6.0\cdot10^{-4}$ |
| CANS-SVD (TF-32) | $6.5\cdot10^{-4}$ | $8.6\cdot10^{-4}$ | $7.1\cdot10^{-4}$ | $7.8\cdot10^{-4}$ |
| CANS-SVD (FP-32) | $3.9\cdot10^{-6}$ | $4.7\cdot10^{-6}$ | $4.1\cdot10^{-6}$ | $4.4\cdot10^{-6}$ |
Table 2. Relative Orthogonality error for different condition number values
| Method | $\kappa_2=1.1$ | $\kappa_2=10$ | $\kappa_2=10^2$ | $\kappa_2=10^4$ |
|---|---|---|---|---|
| CUDA POLAR | $5.5\cdot10^{-6}$ | $4.1\cdot10^{-6}$ | $4.0\cdot10^{-6}$ | $8.1\cdot10^{-6}$ |
| CUDA QR | $1.4\cdot10^{-5}$ | $8.9\cdot10^{-6}$ | $1.3\cdot10^{-5}$ | $1.4\cdot10^{-5}$ |
| CUDA JACOBI | $2.9\cdot10^{-3}$ | $2.1\cdot10^{-3}$ | $2.1\cdot10^{-3}$ | $2.3\cdot10^{-3}$ |
| CANS-SVD (TF-32) | $3.1\cdot10^{-6}$ | $3.1\cdot10^{-6}$ | $3.0\cdot10^{-6}$ | $2.7\cdot10^{-6}$ |
| CANS-SVD (FP-32) | $3.1\cdot10^{-6}$ | $3.1\cdot10^{-6}$ | $3.0\cdot10^{-6}$ | $2.7\cdot10^{-6}$ |
In the table, values highlighted in red correspond to cases where the algorithm failed to compute the SVD.
Low-Rank Case
A substantial part of our evaluation focuses on the behavior of the algorithms on low-rank matrices. For iterative schemes, convergence can be significantly harder to achieve when the input matrix is not full rank. To illustrate this phenomenon, the figure below compares performance on randomly generated low-rank matrices.
Since orthogonality error remains consistent across ranks, we focus on reconstruction error for matrices $A \in \mathbb{R}^{4096 \times 4096}$ with varying rank (see Appendix).
Table 3. Relative Reconstruction error for different ranks
| Method | $r=16$ | $r=256$ | $r=4095$ | $r=4096$ |
|---|---|---|---|---|
| CUDA POLAR | $7.2 \cdot10$ | $7.6\cdot10$ | $7.6\cdot10$ | $2.4\cdot10^{-6}$ |
| CUDA QR | $4.3\cdot10^{-7}$ | $8.7\cdot10^{-7}$ | $1.7\cdot10^{-5}$ | $1.6\cdot10^{-5}$ |
| CUDA JACOBI | $6.9\cdot10^{-5}$ | $3.8\cdot10^{-4}$ | $2.6\cdot10^{-3}$ | $2.6\cdot10^{-3}$ |
| CANS-SVD (TF-32) | $5.1\cdot10^{-4}$ | $6.4\cdot10^{-4}$ | $8.5\cdot10^{-4}$ | $7.6\cdot10^{-4}$ |
| CANS-SVD (FP-32) | $3.9\cdot10^{-6}$ | $3.4\cdot10^{-6}$ | $8.5\cdot10^{-6}$ | $2.8\cdot10^{-6}$ |
SVD via Polar Decomposition
Let us discuss in more detail how to compute the SVD using the polar decomposition. There is a fundamental relation that connects these two decompositions:
\[A = \underbrace{U V}_{W}{}^\top \;\underbrace{V \Sigma V}_{H}{}^\top,\]where $A = U \Sigma V^\top$ is the SVD of the matrix $A$. It is straightforward to check that $W$ has orthonormal columns and that $H$ is symmetric positive semidefinite. Thus, given the SVD, one can easily obtain the corresponding polar decomposition.
However, we want to obtain an equation in the other direction: compute SVD via polar decomposition. The main idea of computing the SVD via the polar decomposition is to first compute the polar factor $W$ using an iterative method and then compute the eigenvalue decomposition of
\[H = W^\top A.\]Since $H$ is symmetric, its eigendecomposition can be computed using well-established algorithms

How to Compute the Polar Decomposition?
The practical approach to computing the polar decomposition is to obtain the orthogonal polar factor using iterative methods. At each step, a specifically chosen function $f_k$ is applied to the singular values of the current iterate. Typically, functions $f_k$ are polynomial-type functions satisfying the relation:
\[X_{k + 1} = f_{k + 1}(X_k) = f_{k + 1}(U \Sigma_k V^\top) = U f_{k + 1}(\Sigma_k) V^\top, \quad X_0 = U \Sigma_0 V^\top.\]These functions are designed so that their repeated composition moves all singular values toward $1$. As a result, $X_k$ converges to the polar factor:
\[X_k \to U V^\top = W, \quad \text{when } f_{k + 1}(\Sigma_{k}) \to I,\]with the choice of $f_k$ strongly influencing convergence speed. Below, we review several typical choices for $f_k$: rational functions (QDWH) and polynomial functions (Newton-Schulz-type iterations).
Rational Functions (QDWH)
There are several iterative methods that are based on rational functions available, including Newton iteration
However, these methods are of limited practical use because they require matrix inversions. To address this, in 2010 Nakatsukasa et al.
Polynomial Functions (Newton-Schulz Iteration)
We next consider the Newton-Schulz iteration
This iteration relies solely on matrix multiplications. Due to this fact, the Newton–Schulz iteration has become increasingly popular in applications. For example, it inspires a core component of the Muon optimizer


Notably, this method converges if $|| X_0 ||_2 < \sqrt{3}$. Therefore, the initial matrix should be normalized before the iteration begins. Ideally, one would divide the matrix by its spectral norm so that $|| X_0 ||_2 = 1$, but computing the spectral norm is expensive. In contrast to Muon, where normalization in Frobenius norm is used, we consider a normalization method based on the $1$-norm and $\infty$-norm from the QDWH implementation in JAX:
\[X_0 = A / \sqrt{\| A \|_1 \| A \|_{\infty}}, \quad \text{since } \| A \|_2 \leq \sqrt{\| A \|_1 \| A \|_{\infty}}.\]The $1$-norm and $\infty$-norm are straightforward to compute, as they correspond to the maximum $\ell_1$ norm of the columns and rows of the matrix, respectively.
Recent studies by Grishina et al.
The iterations produced by these methods are identical under exact arithmetic. However, in Polar-Express, for numerical stability, all polynomial coefficients are divided by $1.01$ except in the final iteration. In contrast, for polynomials of degree $3$ — which are in the central focus of our work, CANS does not employ this technique, as it uses a closed-form solution for the polynomial coefficients.
Why Matrix Multiplications Instead of QR?
In the previous discussion, we argued that matrix multiplications are far more optimized on modern GPUs than QR decompositions. We now support this claim by comparing the execution time of QR decompositions and matrix multiplications (MM) on various GPUs.
As shown in the figure above, for medium-sized matrices, matrix multiplication is significantly faster than QR decomposition, with the gap being particularly large in TF-32 precision, since most GPU libraries do not support QR in TF-32. Notably, the gap between the cost of matrix multiplication and QR widens even further on newer GPU architectures, where MM performance improves much more rapidly than QR. Therefore, whenever possible, it is preferable to perform several matrix multiplications rather than a small number of QR decompositions.
Algorithm Description
In this section, we discuss the CANS-SVD algorithm and the details of its implementation. The procedure begins by preprocessing the input matrix, which pushes small singular values towards $1$ without trying to approximate the unity function. The next step is to compute the polar factor using the CANS iteration from ns_based_iteration.
_A = cans_preprocessing(A) # preprocess matrix A
W = ns_based_iteration(_A) # compute the polar factor of A
H = W.T @ A # obtain H – the symmetric matrix
After obtaining the polar factor, we compute the symmetric eigendecomposition of the matrix $H$ using standard algorithms available in numerical linear algebra libraries, such as those provided in JAX.
V, S = eigh(H) # eigendecomposition of symmetric matrix
U = W @ V
Matrix $A$ can then be decomposed as A = U @ diag(S) @ V.T. However, if $A$ is singular, both QDWH- and NS-based methods converge to a singular matrix $W$, and the resulting matrix $U$ will not be orthogonal.
To address this issue, existing CUDA implementations employ certain engineering workarounds, adding a small perturbation to matrices, as described in the cuSOLVER documentation. Since such perturbations may affect the accuracy of the singular values, we do not use them. Instead, following
if any(abs(norm(U, axis=0) - 1) > eps):
U, _ = qr(U) # compute QR of U to fix orthogonality
# we consider QR with non-negative values on the R diagonal
In most packages, QR does not return $R$ with non-negative diagonal entries. Therefore, we should take into account this fact and multiply columns of $Q$ by signs of non-zero diagonal entries of $R$. In practice, the rank of a matrix cannot be computed stably, so singular cases can be detected by checking whether the column norms of $WV$ are far from $1$.
Related Work
CUDA QR (gesvd)
QR-based algorithms reduce a matrix to bidiagonal form via Householder reflections (or Givens rotations) and then iteratively apply implicit QR steps to compute singular values. These methods are robust and numerically stable, forming the backbone of LAPACK’s SVD routines
However, despite their robustness, QR-based SVD algorithms are not straightforwardly parallelizable: Householder (or Givens) bidiagonalization involves long dependency chains. This makes them GPU-unfriendly and less efficient on modern massively parallel architectures
CUDA Jacobi (gesvdj)
Jacobi-based SVD applies a sequence of plane rotations (Givens rotations) to eliminate the off-diagonal entries of $A^\top A$. At each step, the algorithm picks a pair of columns, computes a $2 \times 2$ rotation that makes them orthogonal, and updates the matrix. Repeating these pairwise orthogonalizations drives the matrix toward a diagonal form.
Since many independent column pairs can be processed simultaneously, the method is highly parallel and well suited for GPUs. The parallelism of the Jacobi method gives the GPU better performance on small- and medium-sized matrices than QR-based methods (cuSOLVER).
CUDA Polar (gesvdp)
The gesvdp routine computes the SVD via polar decomposition followed by an eigenvalue solve. cuSOLVER first obtains the unitary polar factor $W$ of $A$ using the Halley iteration for polar decomposition as described in gesvdp applies syevd to the Hermitian matrix $H = W^\top A$ to extract singular values and right singular vectors.
This design makes gesvdp significantly faster than QR-based gesvd on GPU.
Discussion
The blog post shows how an SVD algorithm based on polar decomposition can be accelerated by replacing the QDWH method (which relies on QR factorizations) with the CANS iteration (which uses only matrix multiplications). However, we do not address the symmetric eigenvalue decomposition, which is also traditionally computed via a sequence of QR iterations and which we have not discussed above. It is therefore likely that this task could also be accelerated by replacing those iterations with faster matrix-multiplication–based methods. We leave this as a direction for future research.
Acknowledgements
The work was supported by the grant for research centers in the field of AI provided by the Ministry of Economic Development of the Russian Federation in accordance with the agreement 000000C313925P4E0002 and the agreement with HSE University № 139-15-2025-009. The calculations were performed in part through the computational resources of HPC facilities at HSE University
Appendix
For the first part of our experiments, we consider square random matrices $A \in \mathbb{R}^{n \times n}$ with condition number $\kappa_2 = 10$. Formally, we generate two random matrices $G_1$ and $G_2$ with i.i.d. entries drawn from the standard Gaussian distribution. We then obtain matrices $U$ and $V$ as the Q factors from the QR decompositions of $G_1$ and $G_2$, respectively, and construct
\[A = U \Sigma V^\top,\]where $\Sigma$ is a diagonal matrix with entries $\sigma_i = \kappa_2^{(n - i) / (n - 1)}$. This procedure allows us to generate random matrices with prescribed condition numbers.
We generate random matrices with a fixed rank $r$ using a similar scheme, except that
\[\sigma_i = \begin{cases} 1, & i \le r, \\ 0, & \text{otherwise}, \end{cases}\]so that the resulting matrix has rank exactly $r$.
For the CANS algorithm
| TF-32 version | FP-32 version | |
|---|---|---|
degree | $3$ | $3$ |
preprocess_iters | $2$ | $2$ |
delta | $0.99$ | $0.99$ |
max_iter | $50$ | $50$ |
tolerance | $10^{-3}$ | $10^{-5}$ |
PLACEHOLDER FOR ACADEMIC ATTRIBUTION
BibTeX citation
PLACEHOLDER FOR BIBTEX