Computer Use Survey - A Visual Survey of Computer Use Agents
In recent years, AI systems operating on the web and in computer environments have become a major topic of interest for both academia and industry. The goal of this blog is to provide an interesting and interactive survey of historical and recent works on computer use agents. We define key terms used in the literature, catalogue the expansive list of environments and datasets, discuss the evolution of the methodologies, and assess both today’s landscape and possible paths forward.
Introduction
In the last few years, and particularly in the most recent past year, AI systems which operate on the web and in computer environments have become a significant topic of study, for both academia and industry. If readers skim the citations in this review, they will likely notice that many of the works are extremely recent, most within the past year.
The goal of this survey is to organize much of the historical and recent work on computer use agents. First, we define exactly what we mean by “Computer Use” in What is Computer Use. We then define and categorize different environments, datasets and evaluations for computer use agents in Environments and Datasets. Next, we discuss the methodological work in this area in Models and Methods focusing in particular on the recent trend of “LLM Agents” and provide an accessible explanation of this class of systems and trends within this research. Finally, we discuss ongoing trends, areas for improvement and possible safety and ethical concerns brought about by this research in Discussion.
So what has shaped this sudden interest in computer use agents in the first place? What goals are academic and industry researchers trying to serve? The first explanation is that the advent of extremely capable language and vision language models (LLMs / VLMs) has made the goal of autonomous computer use agents suddenly quite plausible. These models, trained now on trillions of tokens scraped from the web, are incredibly powerful few- and zero-shot learners
Computer use is not only difficult in terms of being a long-horizon sequential decision-making problem, but also linguistically challenging and knowledge-laden. Before these large-scale models, language problems required models to be trained from scratch, language understanding was often limited and brittle and few-shot reasoning was almost unheard of. This made it hard to do these computer use tasks. Take a popular web use task example: booking an airline ticket. To solve the problem, you first have to be able to precisely understand a user’s request: what airline they prefer, when they want to travel, etc. The agent also must have quite a bit of both commonsense and specific knowledge about airline ticket purchasing to accomplish this. The agent needs to not only understand the request and know how to navigate the airline website, it also needs to understand things like “I should not book a $10k ticket.” With these capable LLMs, we not only have a backbone which has general capability that can start to make progress on the task, but also have these essential commonsense capabilities to make computer use agents possible.
While the precise timing of this work can be explained by the arrival of these capable models, we should also ask what people are trying to accomplish with computer use agents. Many papers point to automating routine, boring or time consuming tasks as a motivation. Many works list automation of tedious tasks or enhancing user experiences as a motivation. The other common motivations are accessibility; making computers and the Internet more generally accessible to those with disabilities. We elaborate on this further in Discussion.
What is Computer Use
First, we define what we mean here by a “Computer Use” AI system or computer use agent. By this, we mean an agent that interacts dynamically with a computer system or web interface. In the MDP formulation, an agent is a decision maker that observes an environment and takes actions
As we discuss later on in Environments and Datasets, we can define a computer use environment in a number of different ways, from an environment which is a simulation or Virtual Machine instance of an operating system, an environment which contains the text of a website(s) which can be navigated, an environment which emulates a browser to navigate and act on a live or cached version of the web or any portion or simulation of a computer that can be operated like an environment. These environments allow for any number of tasks from navigation to question answering. This definition suggests that the thing we care about is looking at works which create agents or environments with the goal of creating AI which can operate on computer systems in a manner similar to the ways humans do. This can actually incorporate many kinds of AI systems, but the most recent version of these which we discuss in detail in Models and Methods is the LLM or VLM agent on computer use environments.
Environments and Datasets
The landscape of computer use research spans diverse environments, from desktop operating systems to web browsers and mobile platforms. Each environment presents unique challenges and opportunities for developing autonomous agents. Below, we present an interactive exploration of the major datasets and benchmarks that have shaped this field.
We divide the datasets into several broad categories. Computer and OS Control describes environments which give more or less full simulated access to a computer or operating system. Web Control and Navigation describes environments where access is mostly to the web (live or statically defined pages). Text-Only Web Environments describe specifically versions of web environments with just text. Web QA and Classification are datasets which ask static questions or classifications on web pages as opposed to controllable environments. Finally we include Coding and Assistant Tasks for coding tasks and the broad category of assistant tasks using computer use elements.
We realize that the category “web browsing” is somewhat vague. It can include tasks involved with changing the settings of a browser such as Chrome and tasks requiring finding information on the web
While going through all of these environments and datasets, we had a number of observations we thought were important to discuss.
First, unlike with many large-scale datasets in other fields such as ImageNet
Second, we found it actually quite difficult to count the number of tasks versus number of instances. In many datasets, there is no real distinction made: each query to a web agent is considered a task and there is exactly one instance of that task. Some of these tasks can be similar or overlap, but there is no categorization of similar tasks or instances. In general, we try to report the size of the dataset in terms of the number of queries unless the dataset has a firm distinction between a task and instance, in which case we report both.
Finally, we note that, especially recently, there are an enormous number of datasets in this area, each with their own data, methodology of collection and input and action spaces. One challenge the field will have going forward is having consistent evaluations and deciding how we are making progress in the field given this. Several papers now have discussed various issues with evaluation
Models and Methods
In this section we discuss the models and methodologies used in the field, from the pre-LLM era (Pre-LLM Work) to Computer Use LM Agents (Computer Use LM Agents) where we discuss Base Models (Base Models) and the wrappers or “Firmament” around them (Firmament), and proprietary systems and products (Proprietary Systems).
Pre-LLM Work
Inherent to this problem is taking repeated actions over time on some representation of a computer interface or website. Naturally, then, works have framed their methodology through the agent/environment paradigm discussed in What is Computer Use. Let’s journey through time to see how these approaches evolved:
Other papers explored various ideas such as curriculum approaches
Computer Use LM Agents
As LLMs and VLMs began to scale on massive amounts of web data and thus became far more capable on language and vision tasks
These papers are often called “agents” or “agentic” to mean that the system can take repeated actions over time by creating a finite state machine construction in such a way that the system is able to repeat a cycle of reading the task query, planning, interpreting the current input and taking actions in the environment. This bears some resemblance to the sense-think-act cycle in robotics
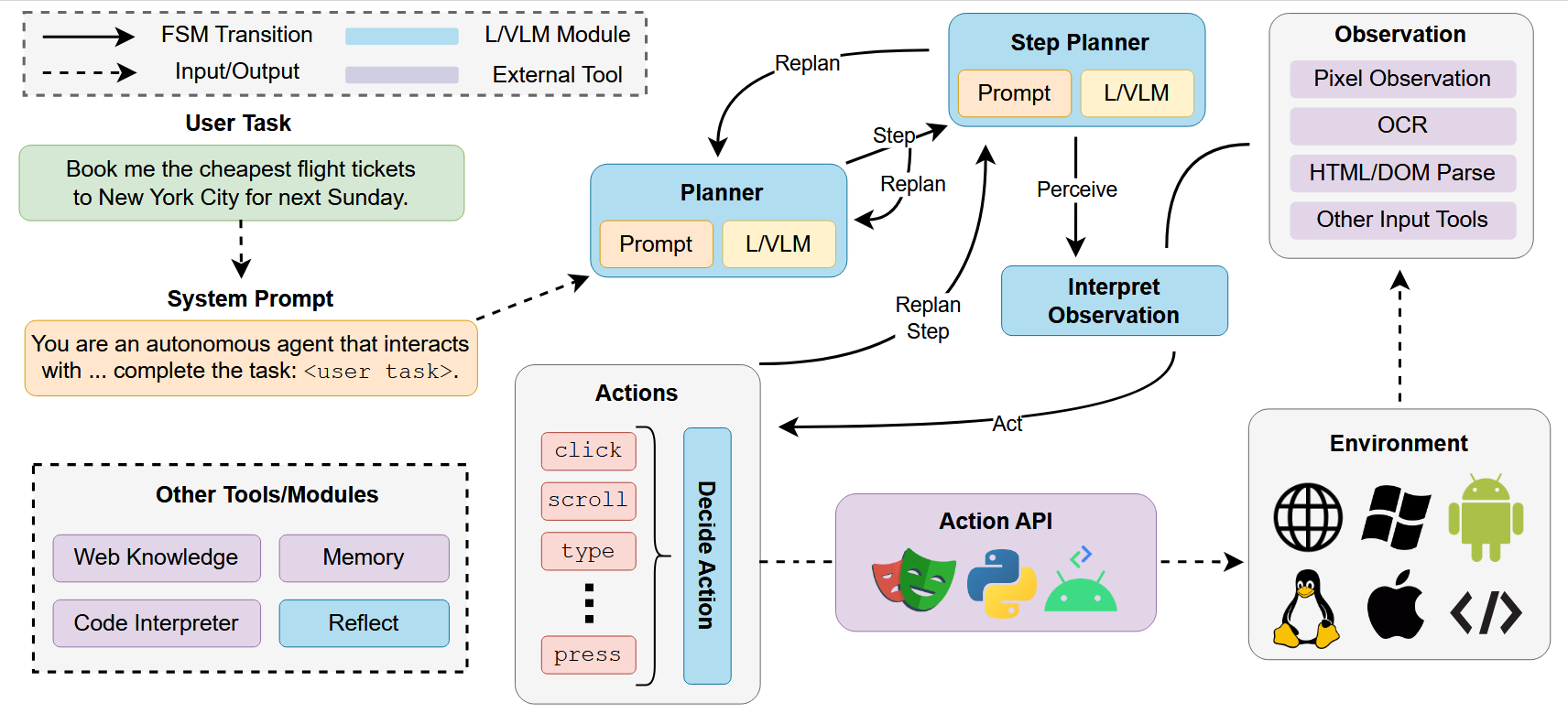
We can think of the diagram as showing how control passes between differently prompted versions of the LLM or VLM (a planner or step planner, an input interpreter, an action decider as well as other kinds of modules such as a reflect module) and external/non LLM components. The user query (i.e. a question or goal the agent is asked to perform) is taken as input to an LLM prompted to act as a planning module. After an initial plan, control is passed to the LLM prompted to plan each step, which calls other modules to load and interpret the input and decide the action.
The input can either be a direct image of the environment, or some combination of the image observation, OCR outputs, parsed HTML code or DOM elements or other representations from the environment. Then the action is decided (or no action is taken and the step is replanned) and passed to a module which interprets the LLM output string as an environment action. This can either be a direct API call (e.g. click(X, Y) or type(str)) or a custom action space which is then parsed and interpreted into a corresponding environment action. This loop continues until the planner decides that the agent has fulfilled the user query and action terminates. We call such agents Computer Use LM Agents.
We can say that what all of these have in common are:
- An LLM or VLM backbone as well as any software that handles API calls if using an external service.
- What we will here call the firmament which is the finite state machine that decides the control flow and the prompting used for different LLM components.
- External tools or modules used.
The differences then between different methods which use this framework can be differentiated in several ways including:
- Differences in base models including whether it is a VLM or LLM using only text observations, and whether and how the base model is trained.
- Differences in the firmament in the exact control flow used, which external modules are called, how the input and output spaces are represented.
- Whether there is any test-time expansion of the base model and how that is handled.
- The input can be a direct image, OCR outputs, parsed HTML, DOM elements, or other representations.
- The action is decided and passed to a module which interprets the LLM output string as an environment action.
- This loop continues until the planner decides the agent has fulfilled the user query.
These modules are not all necessary or exhaustive (some methods include reflect operations and others have a simplified control flow). Different methods will add unique modules such as episodic memory
Base Models for LLM Agents
Possibly the most important design decision that can be made is the choice of base model and whether it is fine-tuned for the task. This is generally decided by the general ability of the model as well as practical considerations such as cost or ability to run or train on the researcher’s available hardware.
Fixed Base Models
The first category of work does not train the LLM backbone, but relies on innovations in the firmament components or adding new modules such as OCR. Much of the early LLM agent work on web agents uses prompted only GPT-4(V)
Supervised Finetuning
Because base VLMs and LLMs are trained on typical web images and text, certain text and images may be out of distribution and models will struggle on these tasks
RL/Exploration Finetuning
Similarly, there have been many works looking at automatic exploration or web and OS environments for finetuning
WEBRL
Multi-task Agent Foundation Models
Most recently, a very popular approach has been to build new foundation models which include web agent data
Firmament
Another critical part of web agent architectures is the control flow state machines and prompting techniques (which we here call the firmament but others might call scaffolding). This incorporates things such as prompting strategies such as prompting agents to give responses in code
One interesting area is in incorporating test-time search into the agent
Another important aspect of all of these frameworks is how they specifically interact with the Web or OS environment itself. For the representation of the input, there has been great experimentation ranging from set of marks
The wide variety of inputs used by different models can often create issues with evaluations and benchmarking models. As shown in Table 5 of OSWorld

Similarly, methods have a wide variety of ways of dealing with the action spaces in the environment. In the earliest works, the action space was at the lowest level, made up of atomic mouse (x, y) positions and click actions
With these custom action spaces, prompts are used to tell the LLM the set of available actions and some kind of parser or interpreter is used to translate these language-specified actions to the environment. The input and action spaces are often tightly linked. For instance in works such as
Proprietary Systems
It is also worth mentioning that Web and OS control agents are not only an academic topic, but an emerging product area for AI companies. Google DeepMind has announced Project Mariner
Some of these projects have reported numbers on some popular computer use benchmarks, but none of these projects have released papers or detailed technical reports, so details about how the agents work and how the evaluations were conducted are not known. Based on the limited information released, it seems apparent that these agents correspond with the line of work described in Computer Use LM Agents, but other details such as how the base models are fine-tuned, data used for training etc are not known. Ultimately, these black-box releases are very relevant to the interest in computer use agents, but cannot be easily benchmarked or relied upon to contribute to the academic literature. This will likely continue to be a tension going forward, as it has been in the broader literature of LLMs.
Discussion
Areas for Improvement
In the next table, we (non-exhaustively) look at the performance of different methods on two popular computer/web agent tasks, WebArena
| Base Models | WebArena-Lite | WebArena | OSWorld |
|---|---|---|---|
| GPT-3.5 Turbo | – | 6.2 | – |
| GPT-4 | – | 14.4 | 12.24 |
| GPT-4o | 13.9 | 13.1 | 11.36 |
| LLAMA2-7B | – | 1.2 | – |
| LLAMA2-70B | – | 0.6 | – |
| Llama3.1-Instruct | 4.8 | – | – |
| ScribeAgent + GPT-4o | 53 | – | – |
| AgentSymbiotic | 52.1 | – | – |
| WebRL | 49.1 | – | – |
| Learn-by-Interact | 48 | – | – |
| AgentOccam-Judge | 45.7 | – | – |
| NNetscape navigator | – | 7.2 | – |
| AutoWebGLM | – | 18.2 | – |
| AWM | – | 35.5 | – |
| WebPilot (GPT-4o) | – | 37.2 | – |
| ExACT | – | – | 19.39 |
| Agent S | – | – | 20.58 |
| OpenCUA | – | – | 34.8 |
| Seed1.5-VL | – | – | 40 |
Progress on popular benchmarks WebArena
One observation to make here is that great improvements have been made on all of these tasks, but that accuracies on these tasks are still quite low, all below 60%, and many of the higher numbers are quite recent! And more recent benchmarks such as
Planning
One area where computer use agents often get stuck is planning. A common issue is that LLM agents will sometimes get stuck in a state and repeatedly try to perform some action unsuccessfully or being distracted by an irrelevant web element. An analysis in Figure 3 of WebRL

As mentioned earlier, many works try to solve this issue with either using an LLM as a “planner”, relying on the LLM itself to recognize that it is stuck, or using some test-time search to escape loops
Input/Output Representation
Another issue is environment grounding, which can take many forms. For agents which use the raw pixel input of the environment, this is a problem of visual grounding (see
A common qualitative issue mentioned in many papers is important UI elements not being recognized by the system, either due to a specific failure in the tool representing the input (e.g. failures of the non-visual tools used to represent the input such as Set-of-Marks
Lack of Training Data
One obvious issue (which is implicit in bad grounding and planning) may be that many base LLMs or VLMs are simply not well aligned to the task because the base models are inadequately trained on this distribution. Attempts have been made to create larger datasets
Long-horizon Problems are Hard
Another answer is simply that many web or computer tasks are difficult because they are fundamentally a long-horizon action problem. We have a description of some task or problem in language and we expect agents to take many consecutive steps before being able to resolve the query. In the Reinforcement Learning literature, there is a well-known issue of having “sparse rewards” facing agents which train on these rewards which makes it difficult for agents to explore properly to reliably find the rewards
Safety/Ethical Concerns
The emergence of more and more capable computer use agents has raised a number of new ethical and safety issues. One prominent issue is the possibility of Web Agents for malicious use. Hard-coded web agents (often colloquially called “bots”) have already been cited as a major issue with so-called “Scalper bots” being used to buy limited-quantity items and resold at massive markups
Another concern is privacy and security. Computer use agents acting on behalf of users have access to extremely sensitive information such as users’ profiles, passwords, financial transactions, social media messages and many other kinds of data
Agentic Web
A recurring discussion point in the philosophy of computer use agents is that current interfaces are built for humans, not autonomous agents. This has motivated arguments for rearchitecting the web for agents rather than forcing agents to reverse-engineer the human-centric interfaces. Stemming from this view, the Agentic Web
On a similar note, Agentic Web Interfaces (AWI)
Agentic Inference Cost
Agentic systems carry a much higher cost multiple than traditional zero-shot LLM/VLM calls, mainly due to running iterative reasoning loops, multi-stage planning, and the “unreliability tax” of retries
While the unit price of tokens has decreased, with some benchmarks seeing performance-adjusted costs drop by 40x annually

But Why Computer Use Agents?
As discussed in the Introduction, the two most common goals for Computer Use Agents are related to automation and accessibility. The automation motivation is compelling - as described in WebGPT
The other motivation is accessibility
There can often be a large disconnect between the use cases, datasets and models thought up by researchers (often mostly sighted people) and those actually important and useful to blind and visually impaired people. As noted in
Nevertheless, the potential certainly exists in the future for these agents to be useful for accessibility, not just by those with visual impairment, but people with severe neuropathy or motor control symptoms as well as people with cognitive or memory issues which might make common web tasks difficult. Computer use agents will first have to drastically improve in performance and researchers will have to work with health researchers, providers and affected people to develop truly useful accessibility features using this technology.
Author’s Note
This survey was adapted from the original interactive web version created by the authors. We tried to take advantage of the web as a medium, specifically to make the survey a bit different and more interactive for readers. In addition, certain parts of the survey, such as the list of datasets, would simply not have worked in a normal linear blog. Claude Sonnet 4 was used to help build the website. Special thanks to Dai-Jie Wu for providing valuable feedback and helping debug browser compatibility issues.
Author Contributions
Initial paper collection was done jointly by KM and AM. Most sections were written by KM, except for Environments and Datasets, which were split between KM and AM, and Agentic Web and Inference Cost, which were written by MFI. The original website was created with Claude Sonnet 4, and the transfer from the original website to the blog was done by MFI. Final editing was done by both KM and AM.
Enjoy Reading This Article?
Here are some more articles you might like to read next: