The Lottery LLM Hypothesis, Rethinking What Abilities Should LLM Compression Preserve?
Motivated by reducing the computational and storage costs of LLMs, model compression and KV cache compression have attracted much attention from researchers. However, current methods predominantly emphasize maintaining the performance of compressed LLMs, as measured by perplexity or simple accuracy on tasks of common sense knowledge QA and basic arithmetic reasoning. In this blog, we present a brief review of recent advancements in LLMs related to retrieval-augmented generation, multi-step reasoning, external tools, and computational expressivity, all of which substantially enhance LLM performance. Then, we propose a lottery LLM hypothesis suggesting that for a given LLM and task, there exists a smaller lottery LLM capable of producing the same performance as the original LLM with the assistance of multi-step reasoning and external tools. Based on the review of current progress in LLMs, we discuss and summarize the essential capabilities that the lottery LLM and KV cache compression must possess, which are currently overlooked in existing methods.
Current Efforts on Compressing LLMs and KV Cache
LLMs have demonstrated remarkable proficiency in natural language processing, enabling sophisticated interactions and understanding of human language
Compression methods. To this end, both academic researchers and industrial engineers are trying to compress model parameters and reduce the model to a smaller one while keeping its performance unchanged. The typical compression algorithms include pruning
Missed aspects. Some recent studies show that LLMs may lose their crucial advanced abilities under compression, such as long-context retrieval, long-context generation, and long-document reasoning
In the following sections, we examine recent advancements in retrieval-augmented generation, the utilization of external tools, and multi-step reasoning, all of which markedly enhance the performance of LLMs. Subsequently, we introduce the lottery LLM hypothesis, which posits that for a specific LLM and task, a smaller lottery LLM can achieve equivalent performance to the original LLM, aided by multi-step reasoning and external tools. Drawing from the review of current LLM advancements, we discuss and outline the critical capabilities that the lottery LLM and KV cache compression should encompass, which are currently neglected in existing methodologies.
Tackling Redundant and Unreal Knowledge of LLMs with Knowledge Retrival
Redundant Knowledge. In contemporary applications, many individuals utilize LLMs as encyclopedic resources or to verify news and academic research, akin to an Internet search engine. Recent studies indicate that LLMs exhibit varying performance in knowledge retrieval, contingent upon the popularity of the information
Hallucinated Knowledge. LLMs often generate unreal outputs rather than factual knowledge, a phenomenon known as hallucination
Retrieval Augmented Generation (RAG). Large Language Models (LLMs) exhibit robust in-context learning capabilities, enabling them to respond to queries using prompts rather than relying solely on their internal knowledge encoded within model parameters. Consequently, external knowledge sources such as scholarly articles, web pages, books, and other documents can be integrated into prompts to facilitate the retrieval of additional factual information
Is it necessary to store all knowledge within LLM parameters if RAG can accurately retrieve factual information from external knowledge bases? If not, which knowledge should be stored and which should not?
Considering two extreme scenarios:
- Storing all knowledge in model parameters: If all knowledge is stored within model parameters, LLMs function as oracle machines, obviating the need for RAG. However, training such an LLM is nearly impossible because not all knowledge can be collected and never become outdated
. Moreover, deploying such a large model is inefficient. - Storing all knowledge in external knowledge bases: If all knowledge is stored externally, LLM parameters could potentially be reduced significantly, allowing for the retrieval of factual information during inference.
Nevertheless, LLMs require foundational common knowledge to perform tasks such as reasoning and accurate retrieval. This issue will be further explored in subsequent sections. Thus, compressing all knowledge into external knowledge bases is not feasible. Investigating the nature of learned knowledge and identifying which knowledge triggers the grokking phenomenon in LLMs remains an open research question
Trade-off between model size and knowledge base. Some studies indicate that adaptive knowledge retrieval is a promising direction to enhance the performance of LLMs and may help to find an optimal trade-off between the knowledge base and model size
The core idea of adaptive RAG appears to be related to a classic efficient data structure, Huffman coding
Finetuning vs. retrieval. Another related question is whether finetuning should be used to enhance the performance of LLMs in specific application domains such as legal, finance, and medical fields
Beyond the RAG. Document-based knowledge retrieval primarily assists LLMs in retrieving knowledge of triplets consisting of entity, relation, and object
External Tools
Advanced Large Language Models (LLMs) demonstrate remarkable capabilities in function calling, which involves invoking external tools for addressing specific tasks. These external tools may include Internet search engines
Arithmetic Function Calls. To solve arithmetic problems, LLMs are trained on arithmetic datasets
Internet Search Engine. To augment LLM knowledge with online and dynamically updated external information, the Internet search engine is employed as an external tool
LLM Operating System (OS). By conceptualizing LLM calls as system calls akin to traditional operating systems, recent studies propose developing a new LLM-as-OS framework
Logic Solver. There is ongoing debate regarding whether LLMs can perform logical reasoning akin to humans
Computational Expressivity of LLMs
Basic Transformer Architecture. Basic transformers, devoid of intermediate decoding steps, exhibit limited computational expressivity
Decoding-based Transformers. Decoding-based transformers generate output sequentially, word by word, rather than producing a single answer. This approach enhances their computational expressivity compared to basic transformers, with expressivity increasing in tandem with the length of the decoding steps
Decoding with External Memory. Research suggests that external memory can enhance the computational expressivity of LLMs
Multi-step Reasoning
The Chain-of-Thought (CoT) reasoning paradigm demonstrates that engaging in detailed, step-by-step reasoning can significantly enhance the performance of Large Language Models (LLMs) compared to single-step reasoning
Single LLM Call. CoT exemplifies a single LLM call, utilizing the model once. Beyond explicit prompting to initiate detailed reasoning, recent studies propose enabling LLMs to execute advanced search algorithms during the decoding process, such as Monte-Carlo Tree Search (MCTS)
Multiple LLM Calls. Some approaches advocate for multiple LLM calls, which operate independently of each other, potentially yielding correct answers across these calls
Planning and Scheduling. The essence of multi-step reasoning lies in decomposing the original problem into multiple sub-problems and addressing them sequentially. This process involves planning and scheduling. To facilitate autonomous planning and scheduling, recent studies propose employing LLMs as meta-agents to orchestrate planning and scheduling, wherein the original problem is decomposed, and the meta-agent delegates sub-problems to other LLMs based on the schedule
Lottery LLM Hypothesis
Consider an original language model $f_\theta$ parameterized by the $\theta \in \mathbb{R}^{k_{\theta}}$, capable of processing input of token length $n$, and an input problem $q \in \mathbb{R}^{m\times h}$ with token length $m < n$ and ground truth $\mu \in \mathbb{R}^{l\times h}$. The problem $q$ is a question consisting of a sequence of words. And the $\mu$ is also a sequence of words representing the answer to the question $q$. $h$ is the dimension of the word embedding. The performance of the model is evaluated using a performance measure $P(\cdot)$, expressed as $P(f_\theta(q), \mu)$ which maps its inputs as a scalar value. We hypothesize the existence of a smaller language model $g_\phi$ with parameters $\phi \in \mathbb{R}^{k_{\phi}}$ ($k_{\phi} < k_{\theta}$) and the same input length $n$, which can solve the problem $q$ with performance comparable to $f_\theta$, such that:
\[P(f_\theta(q), \mu) \leq P( \mathcal{A}_{g_\phi, \mathcal{D}, \mathcal{R}, \mathcal{C}, \mathcal{M}}(q), \mu),\]where $\mathcal{A}$ represents a reasoning algorithm that may involve one or multiple invocations of $g_\phi$ with various inputs, including the original problem $q$, documents $d \in \mathcal{D}$ retrieved from the external knowledge base $\mathcal{D}$, or function calls $c \in \mathcal{C}$ retrieved from external tools $\mathcal{C}$ using the retriever $\mathcal{R}$. Each document $d \in \mathbb{R}^{n_d\times h}$ is a vector of words. While the function calls $c: \mathbb{R}^{n_c^i\times h} \to \mathbb{R}^{n_c^o\times h}$ is a provided function. The knowledge base $\mathcal{D}$ is a vector database storing vector documents as key-value pairs, and $\mathcal{M}$ denotes the external memory that stores intermediate results. All $\mathcal{D}$, $\mathcal{C}$, and $\mathcal{M}$ are sets. And items in $\mathcal{D}$ and $\mathcal{C}$ are key-value pairs depending on the specific tasks, like vector database
The reasoning algorithm $\mathcal{A}$ is described as Algorithm 1, employing a divide-and-conquer strategy to solve the original problem $q$. This dynamic divide-and-conquer methodology is versatile and applicable to numerous contemporary reasoning algorithms.

Recursive and Dynamic Scheduling. Algorithm 1 can encompass tree-based reasoning methods such as Tree-of-Thought (ToT)
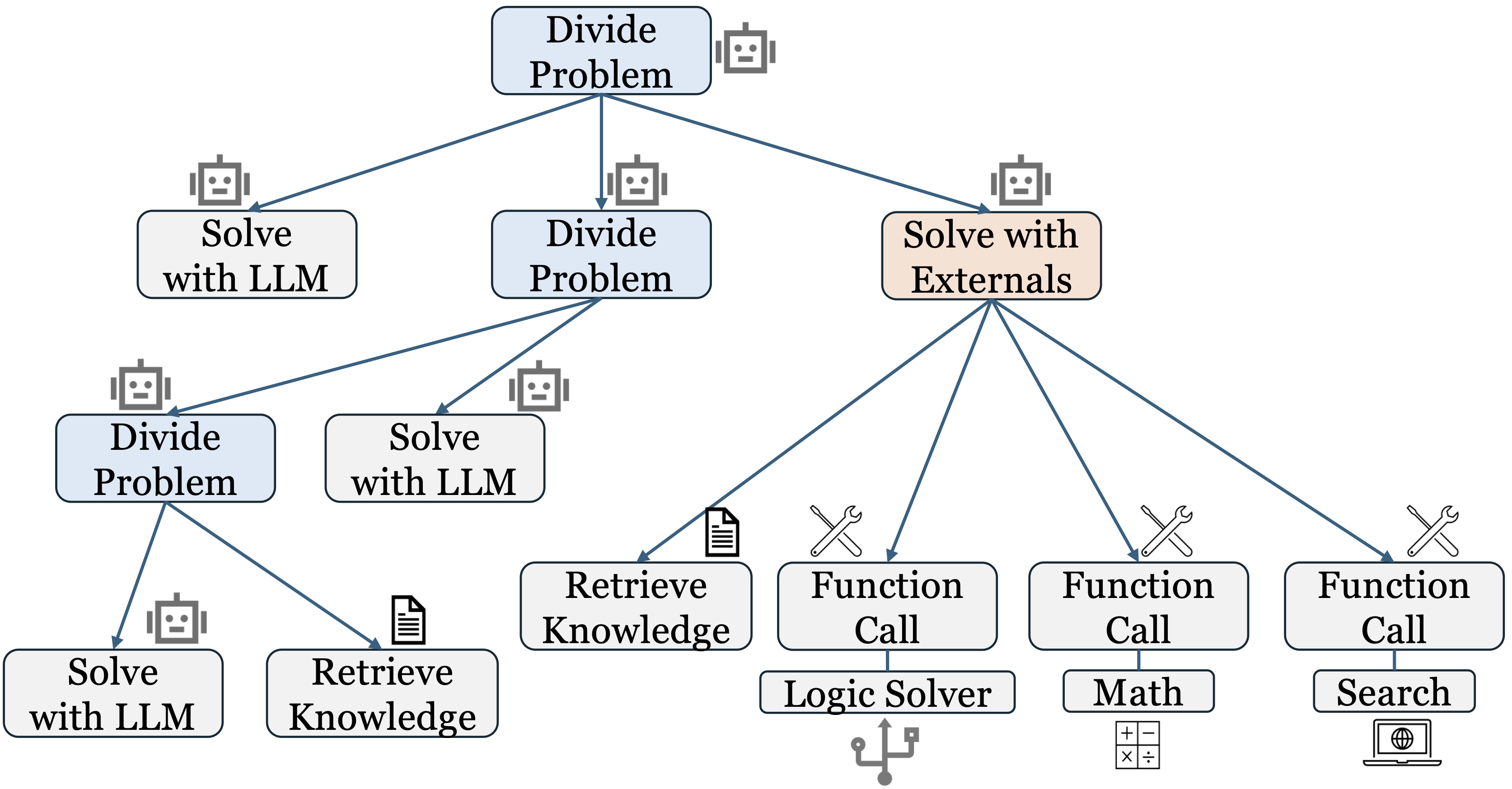
External Knowledge and Tools. During each phase of problem-solving, Algorithm 1 initially assesses whether the problem can be directly addressed using the external knowledge base $\mathcal{D}$ or external tools $\mathcal{C}$. If so, Algorithm 1 utilizes $g_\phi$ to evaluate the problem $q$ and ascertain the necessary knowledge or tools required for its resolution. Subsequently, based on the generated requests, the retriever $\mathcal{R}$ searches for external knowledge $d \in \mathcal{D}$ or tool $c \in \mathcal{C}$ to provide the requisite results. These supplementary results are then integrated with the problem $q$ for resolution by the model $g_\phi$. This framework facilitates the application of Retrieval Augmented Generation (RAG) and external tools, such as arithmetic calculation functions, Internet search engines, and logic solvers, to effectively address the problem $q$.
External Memory. The external memory $\mathcal{M}$ functions as a repository for storing intermediate results throughout the reasoning process. When tackling various sub-problems, intermediate results can be stored in the external memory for reuse in subsequent steps. By interacting with the external memory, Algorithm 1 can emulate reasoning methods that utilize working memoryDivide_and_Conquer function in Algorithm 1 is not constrained. Through careful design and programming, the recursive mechanism can execute fundamental operations such as MOV, COPY, JUMP, and WRITE and READ from the external memory, thereby simulating a Turing machine
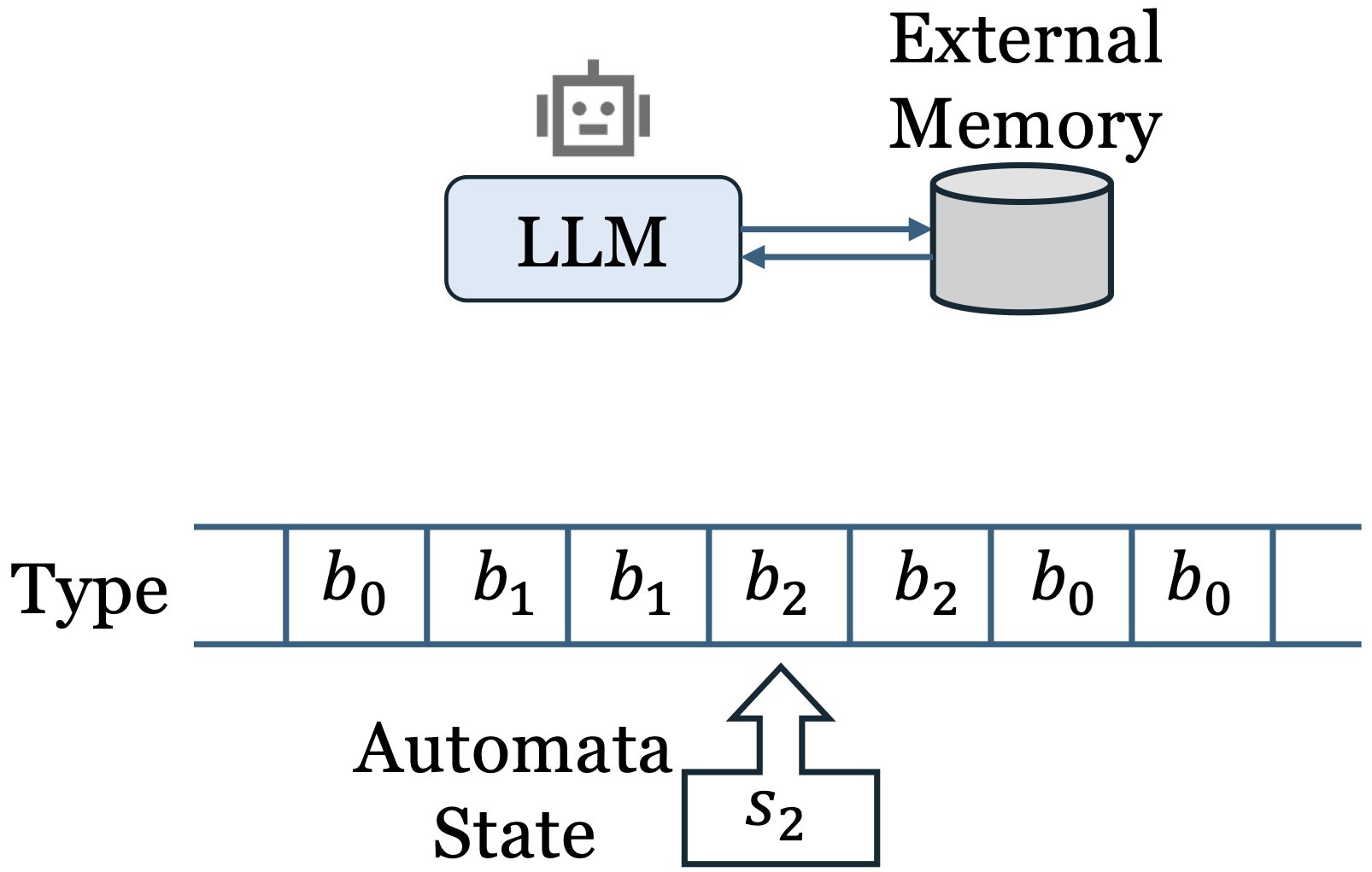
Most of previous model compression
Ability 1: Retrieval from prompts. Obviously, the useful information in the prompts related to addressing the problem $q$ is crucial for the lottery LLM. After collecting the required external results into the prompt, the LLM $g_\phi$ needs to be able to retrieve the required information from the prompt and avoid the interruption of some irrelevant information. This is related to the retrieval ability of the LLM and its measurement test is like the well-known needle-in-the-haystack(NIAH) test
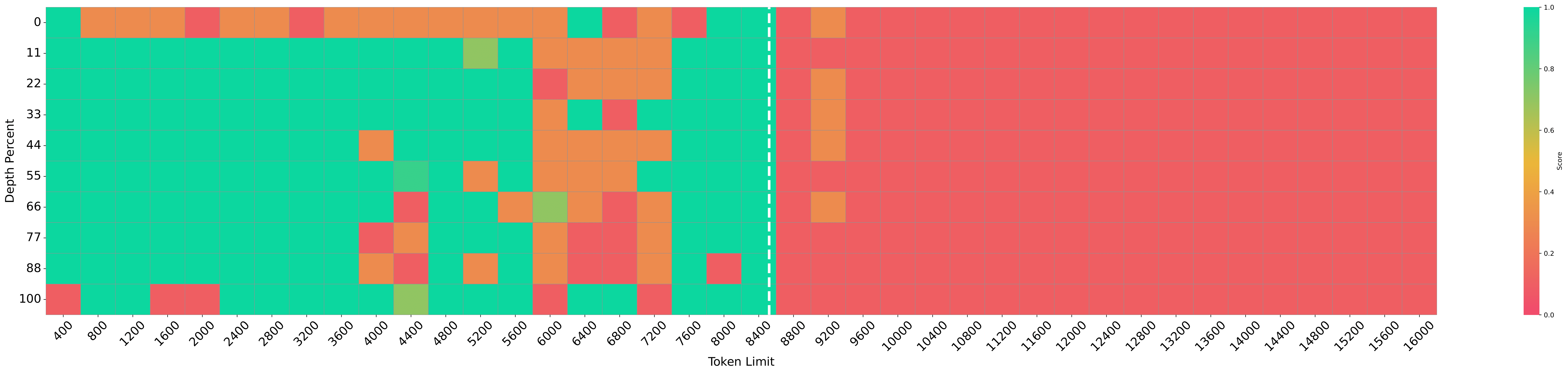
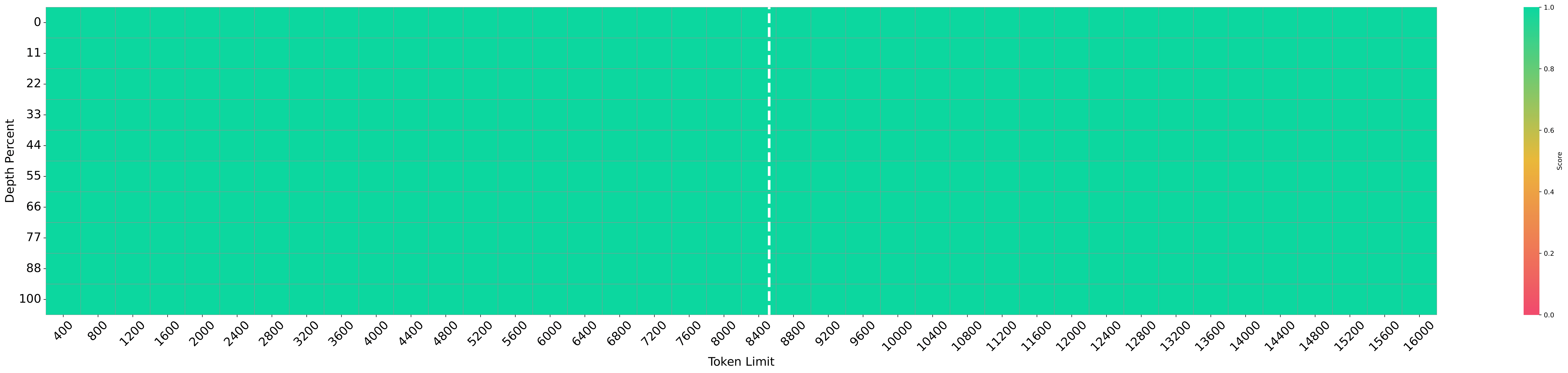
The figures illustrate that preprocessing prompts markedly enhance the performance of LLMs on the NIAH test. Importantly, even when the input length surpasses the model’s context size (8K tokens for LLaMA3-8B-Instruct), there is no observed degradation in performance. This indicates the potential of utilizing preprocessed prompts to augment the retrieval capabilities of LLMs.
Ability 2: Identification of Required External Resources. To effectively determine which external resources to utilize, such as knowledge databases or external tools, the LLM $g_\phi$ must possess the capability to comprehend and correlate the problem $q$ and its associated sub-problems with the relevant resources. Consequently, $g_\phi$ should have foundational knowledge of the problem $q$ and the external resources. Additionally, it must exhibit a strong ability to associate queries with the available resources. When external tools are adeptly employed, the performance of smaller LLMs can be significantly enhanced. The subsequent table presents the results of arithmetic problem-solving using various LLMs and methodologies. The PAL
| GSM8K | SVAMP | ASDIV | ADDSUB | MULTIARITH | |
|---|---|---|---|---|---|
| DIRECT Codex | 19.7 | 69.9 | 74.0 | 90.9 | 44.0 |
| CoT UL2-20B | 4.1 | 12.6 | 16.9 | 18.2 | 10.7 |
| CoT LaMDA-137B | 17.1 | 39.9 | 49.0 | 52.9 | 51.8 |
| CoT Codex | 65.6 | 74.8 | 76.9 | 86.0 | 95.9 |
| CoT PaLM-540B | 56.9 | 79.0 | 73.9 | 91.9 | 94.7 |
| CoT Minerva 540B | 58.8 | - | - | - | - |
| PAL | 72.0 | 79.4 | 79.6 | 92.5 | 99.2 |
Besides, with provided the external documents, following results
| Method | LLM | PopQA (acc) | NQ (acc) | ASQA (str-em) | ASQA (hit) |
|---|---|---|---|---|---|
| CoT without RAG | Llama-3-Ins8B | 24.8 | 44.0 | 28.8 | 7.8 |
| CoT without RAG | Llama-3-Ins70B | 31.6 | 54.4 | 36.4 | 11.2 |
| CoT without RAG | ChatGPT-4oMINI | 32.4 | 53.2 | 32.4 | 8.0 |
| With RAG | Llama-3-Ins8B | 59.8 | 54.0 | 38.8 | 14.0 |
Ability 3: Planning and Scheduling. To effectively decompose the problem $q$ into multiple sub-problems and address them sequentially, the LLM $g_\phi$ must possess robust planning and scheduling capabilities. This competency is essential for the lottery LLM to tackle complex problems efficiently. Consequently, the LLM $g_\phi$ should have a comprehensive understanding of both the primary problem $q$ and its constituent sub-problems. However, the intricate details of solving these sub-problems may not be necessary for the LLM $g_\phi$, as external resources can be leveraged to resolve them. Moreover, proficient scheduling is crucial for the lottery LLM to enhance reasoning efficiency.
The table below illustrates the performance of LLMs using simple inference compared to those employing a strategy of decomposing the problem into sub-problems and utilizing external logic solvers, such as Logic-LM
| Dataset | ChatGPT (gpt-3.5-turbo) | GPT-3.5 (text-davinci-003) | GPT-4 (gpt-4) |
|---|---|---|---|
| PrOntoQA | 47.40 / 61.00 | 51.80 / 85.00 | 77.40 / 83.20 |
| ProofWriter | 35.50 / 58.33 | 36.16 / 71.45 | 52.67 / 79.66 |
| FOLIO | 45.09 / 62.74 | 54.60 / 61.27 | 69.11 / 78.92 |
| LogicalDeduction | 40.00 / 65.67 | 41.33 / 62.00 | 71.33 / 87.63 |
| AR-LSAT | 20.34 / 26.41 | 22.51 / 25.54 | 33.33 / 43.04 |
Ability 4: Precise Approximation of Fundamental Operations. As discussed in the section on the computational expressivity of LLMs, achieving (approximate) Turing completeness necessitates that the LLM $g_\phi$ precisely approximates fundamental operations such as MOV, COPY, JUMP, and WRITE and READ from external memory
Ability 5: Long-Context Reasoning. In single-step reasoning, an extended context length allows the LLM $g_\phi$ to access and utilize more information for problem-solving. In multi-step reasoning, the prompt serves as a form of working memory for the meta-agent, or planner (controller). Each result from solved sub-problems should be incorporated into the prompt for subsequent steps. As problem complexity increases, so does the depth of the sub-problem tree. Therefore, the LLM $g_\phi$ must possess the ability for extended contextual reasoning to support deep tree reasoning
Conclusion
This blog aims to elucidate the potential of the lottery LLM and to summarize the essential capabilities that the lottery LLM should possess, which are currently lacking in existing methods of LLM and KV cache compression. The discussion on redundant knowledge within LLMs also highlights the trade-off between knowledge storage and reasoning capabilities. With the development of the lottery LLM, alongside external tools, knowledge bases, and a robust algorithm $\mathcal{A}$, there is potential for the lottery LLM to function as a meta-agent akin to human cognition. Its external memory could serve as long-term memory, the prompt as short-term memory, and the LLM inference process $g_\phi$ as the fundamental cognitive process. External tools and knowledge bases can be considered as supplementary tools commonly used in daily life. Deploying the lottery LLM could significantly reduce energy and resource consumption in large-scale LLM-driven applications. Future research on LLM compression, KV cache compression, and other efficient LLM methodologies should address both efficiency and the essential capabilities of LLMs.
Acknowledgements
This work was partially supported by National Natural Science Foundation of China under Grant No. 62272122, the Guangzhou Municipal Joint Funding Project with Universities and Enterprises under Grant No. 2024A03J0616, Guangzhou Municipality Big Data Intelligence Key Lab (2023A03J0012), and Hong Kong CRF grants under Grant No. C7004-22G and C6015-23G, contract R6021-20, and RGC GRF grants under the contracts 16200221, 16207922 and 16207423, the MOE Academic Research Fund (AcRF) Tier 1 Grant in Singapore (Grant No. T1 251RES2315).