Factual Context Validation and Simplification: A Scalable Method to Enhance GPT Trustworthiness and Efficiency
As the deployment of Large Language Models (LLMs) like GPT expands across domains, mitigating their susceptibility to factual inaccuracies or hallucinations becomes crucial for ensuring reliable performance. This blog post introduces two novel frameworks that enhance retrieval-augmented generation (RAG): one uses summarization to achieve a maximum of 57.7% storage reduction, while the other preserves critical information through statement-level extraction. Leveraging DBSCAN clustering, vectorized fact storage, and LLM-driven fact-checking, the pipelines deliver higher overall performance across benchmarks such as PubMedQA, SQuAD, and HotpotQA. By optimizing efficiency and accuracy, these frameworks advance trustworthy AI for impactful real-world applications.
Introduction
Large Language Models (LLMs), such as GPT, have advanced natural language processing by offering incredible fluency and adaptability

Existing solutions, including fine-tuning, retrieval-augmented generation (RAG), and post-hoc validation, address specific aspects of this problem but often at the cost of scalability or computational efficiency
In this blog post, we propose an enhancement to RAG pipelines that integrates LLM summarization, clustering with DBSCAN, and vectorized fact storage to tackle the challenges of managing unstructured data
The Challenge of Factual Accuracy in AI
Hallucinations and Trust Deficit
Hallucinations in LLMs arise from their probabilistic design, which prioritizes predicting plausible sequences over verifying factual accuracy
1. Dynamic and Unstructured Contexts
LLMs are trained on vast corpora of text that often lack semantic organization. Moreover, the facts embedded within these datasets are static—reflecting the state of the world at the time of training. However, real-world knowledge evolves dynamically, leaving models unable to adapt without post-training updates
Formalizing the Knowledge Divergence
Let the model’s knowledge at time \(t\) be denoted as \(K(t)\). We can express the knowledge state as: \(K(t) = \textcolor{#5DADEC}{K(t_0)} + \textcolor{#E67E22}{\Delta K(t)},\) where:
- \(\textcolor{#5DADEC}{K(t_0)}\) represents the knowledge at the time of training.
- \(\textcolor{#E67E22}{\Delta K(t)}\) captures incremental updates post-deployment.
In most deployed LLMs: \(\textcolor{#E67E22}{\Delta K(t)} = 0,\) indicating that the knowledge remains frozen at \(\textcolor{#5DADEC}{K(t_0)}\). Over time, as \(t \to \infty\), the divergence between \(K(t)\) and real-world knowledge widens, resulting in increasingly outdated or inaccurate outputs.
Real-World Implications
This static nature is especially problematic in domains such as:
- Medicine, where evolving treatment protocols and research are critical
. - Law, where changes in regulations or precedents can render older knowledge obsolete.
Without mechanisms to dynamically update \(\Delta K(t)\), LLMs fail to provide accurate, timely information in these high-stakes environments.
2. Compounded Errors in Reasoning
In multi-step reasoning, LLMs encounter a cascading error problem, where inaccuracies at each step propagate and amplify in subsequent steps
Quantifying Error Propagation
Let \(P(x_n)\) denote the probability of correctness at reasoning step \(n\). The overall probability of correctness across \(N\) steps is given by: \(P_{\text{total}} = \prod_{n=1}^N \textcolor{#0f941b}{P(x_n)}.\) Since \(\textcolor{#0f941b}{P(x_n)} < 1\) in most real-world scenarios, \(P_{\text{total}}\) decays exponentially as \(N\) increases. This exponential decay illustrates how longer reasoning chains magnify errors, making LLMs less reliable for complex tasks
Modeling Error Interactions
Error propagation can also be modeled using second-order interactions through the Hessian matrix
To represent this interaction in matrix form, the Hessian matrix can be visualized as:
where:
- \(H_{ij}\) quantifies how an error in dimension \(x_i\) interacts with errors in dimension \(x_j\).
- \(\textcolor{#E74C3C}{E}\) is the error function dependent on reasoning dimensions \(x_i\).
This matrix representation highlights the symmetry of the Hessian (\(H_{ij} = H_{ji}\)), demonstrating how second-order effects capture complex interactions between dimensions. By modeling these interactions, we can better understand how errors propagate and amplify through reasoning pathways. This indicates that inaccuracies are not isolated; instead, they cascade through interconnected reasoning pathways, compounding the overall error and making multi-step reasoning increasingly unreliable in LLMs.
Limitations of Existing Approaches
Fine-Tuning
Fine-tuning involves retraining LLMs on domain-specific datasets, improving their factual accuracy within specific contexts
- High resource requirements make it impractical for many organizations and individuals
. - Static knowledge freezes models in time, necessitating constant retraining to stay relevant
. - Specialization often comes at the expense of general-purpose utility, limiting versatility
.
Retrieval-Augmented Generation (RAG)
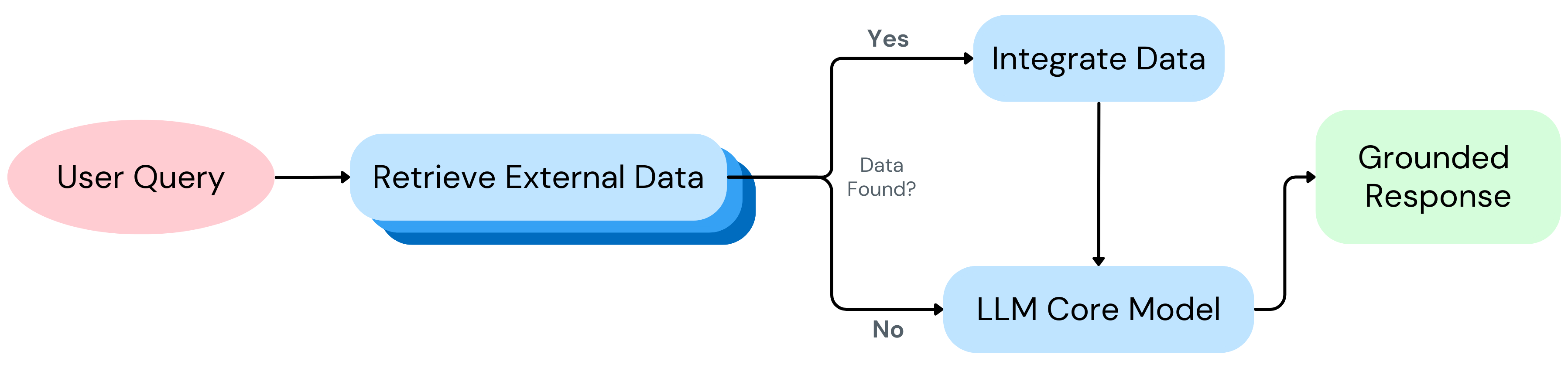
RAG pipelines integrate external knowledge retrieval into the LLM workflow, providing factual grounding by leveraging curated databases or search engines
- Retrieved information may be incomplete, outdated, or biased, directly affecting output reliability
. - RAG systems retrieve information but do not inherently validate it, leaving unresolved conflicts between retrieved facts and the LLM’s internal predictions
. - As query complexity increases, retrieved information can become overly sparse, and the increasing contextual length can diminish its enhancement for the LLM, ultimately restricting scalability
.
Post-Hoc Validation

Post-hoc validation attempts to correct inaccuracies after generation by cross-referencing outputs with external datasets or models
- It introduces latency, making it unsuitable for real-time applications.
- Validating every output, even when unnecessary, wastes computational resources
. - It provides limited feedback for refining the underlying generative process, addressing symptoms but not root causes
.
Theoretical Foundations
Factual Validation: Core Principles
Factual validation ensures that LLM outputs are verifiable and contextually accurate. This approach is guided by two main principles:
-
Granularity: Responses are decomposed into discrete factual units for precise validation, reducing the likelihood of undetected inaccuracies
. Mathematically, a generated response \(R\) is represented as: \(R = \{\textcolor{#1f77b4}{F_1}, \textcolor{#ff7f0e}{F_2}, \dots, \textcolor{#2ca02c}{F_n}\},\) where each \(F_i\) represents a discrete factual unit, such as a statement or claim.
Example:
\[R = \{\text{"Paris is the capital of France"}, \text{"The Eiffel Tower is in Paris"}\}.\]Validation is performed by comparing each \(F_i\) against a knowledge base \(K\), which contains validated information:
\[K = \{\text{"Paris is the capital of France"}, \text{"The Eiffel Tower is in Paris"}\}.\]A factual unit \(F_i\) is considered valid if it exists in \(K\): \(V(F_i) = \begin{cases} 1 & \text{if } F_i \in K, \\ 0 & \text{otherwise.} \end{cases}\)
The overall validation score for the response is calculated as: \(V(R) = \frac{\sum_{i=1}^{n} V(F_i)}{n},\) where \(V(R) \in [0, 1]\) quantifies the proportion of factual units in \(R\) that are verified by \(K\).
-
Scalability: Validation systems leverage vectorized representations to efficiently compare outputs against large, structured knowledge bases
. Instead of exact string matching, factual units \(F_i\) are mapped into a high-dimensional vector space for efficient comparisons.
The Role of Vectorization
Vectorization encodes atomic facts into high-dimensional representations (embeddings) that facilitate efficient storage, retrieval, and comparison
Each factual unit \(F_i\) is transformed into an embedding: \(\mathbf{v}_i = \textcolor{#1f77b4}{\text{Encode}(F_i)},\) where \(\text{Encode}(\cdot)\) maps textual data to numerical vectors.
Example:
\(F_i = \text{"Paris is the capital of France"}\) \(\mathbf{v}_i = [0.12, 0.45, 0.67, \dots, 0.89]\)
The knowledge base \(K\) is also represented as a set of embeddings: \(K = \{\mathbf{k}_1, \mathbf{k}_2, \dots, \mathbf{k}_m\}.\)
To validate \(F_i\), the similarity between \(\mathbf{v}_i\) and \(\mathbf{k}_j\) is measured using cosine similarity: \(\text{Sim}(\mathbf{v}_i, \mathbf{k}_j) = \frac{\mathbf{v}_i \cdot \mathbf{k}_j}{\|\mathbf{v}_i\| \|\mathbf{k}_j\|}.\)
Cosine Similarity: Determines how closely aligned two vectors are in high-dimensional space (range: -1 to 1):
- \(1\): Identical vectors.
- \(-1\): Completely opposite vectors.
A factual unit \(F_i\) is considered valid if: \(\max_{j} \text{Sim}(\mathbf{v}_i, \mathbf{k}_j) \geq \tau,\) where \(\tau\) is a predefined similarity threshold
Combining Granularity and Vectorization
Factual validation combines the precision of granularity with the efficiency of vectorization to determine the validity of responses. The process involves:
-
Decompose Response: Break \(R\) into: \(R = \{\textcolor{#1f77b4}{F_1}, \textcolor{#ff7f0e}{F_2}, \dots, \textcolor{#2ca02c}{F_n}\}.\)
-
Encode Units: Transform each \(F_i\) into its high-dimensional embedding: \(\mathbf{v}_i = \text{Encode}(F_i).\)
-
Compare with Knowledge Base: Use cosine similarity to validate \(\mathbf{v}_i\) against \(K\): \(\max_{j} \text{Sim}(\mathbf{v}_i, \mathbf{k}_j) \geq \tau.\)
The overall validation score is computed as: \(V(R) = \frac{\sum_{i=1}^{n} \mathbb{1} \left( \max_{j} \text{Sim}(\mathbf{v}_i, \mathbf{k}_j) \geq \tau \right)}{n},\) where \(\mathbb{1}(\cdot)\) is the indicator function that outputs 1 if the condition is satisfied and 0 otherwise.
This approach ensures:
- Precision at the component level (granularity).
- Scalability across large knowledge bases (vectorization)
.
Our Proposal: Fact-Based Validation for GPT Systems
To address the challenges of ensuring factual accuracy in GPT systems, we propose a framework that preprocesses data into structured and verifiable units for use in fact verification with the aim to enhance the reliability of LLM-generated responses while optimizing storage and retrieval efficiency.
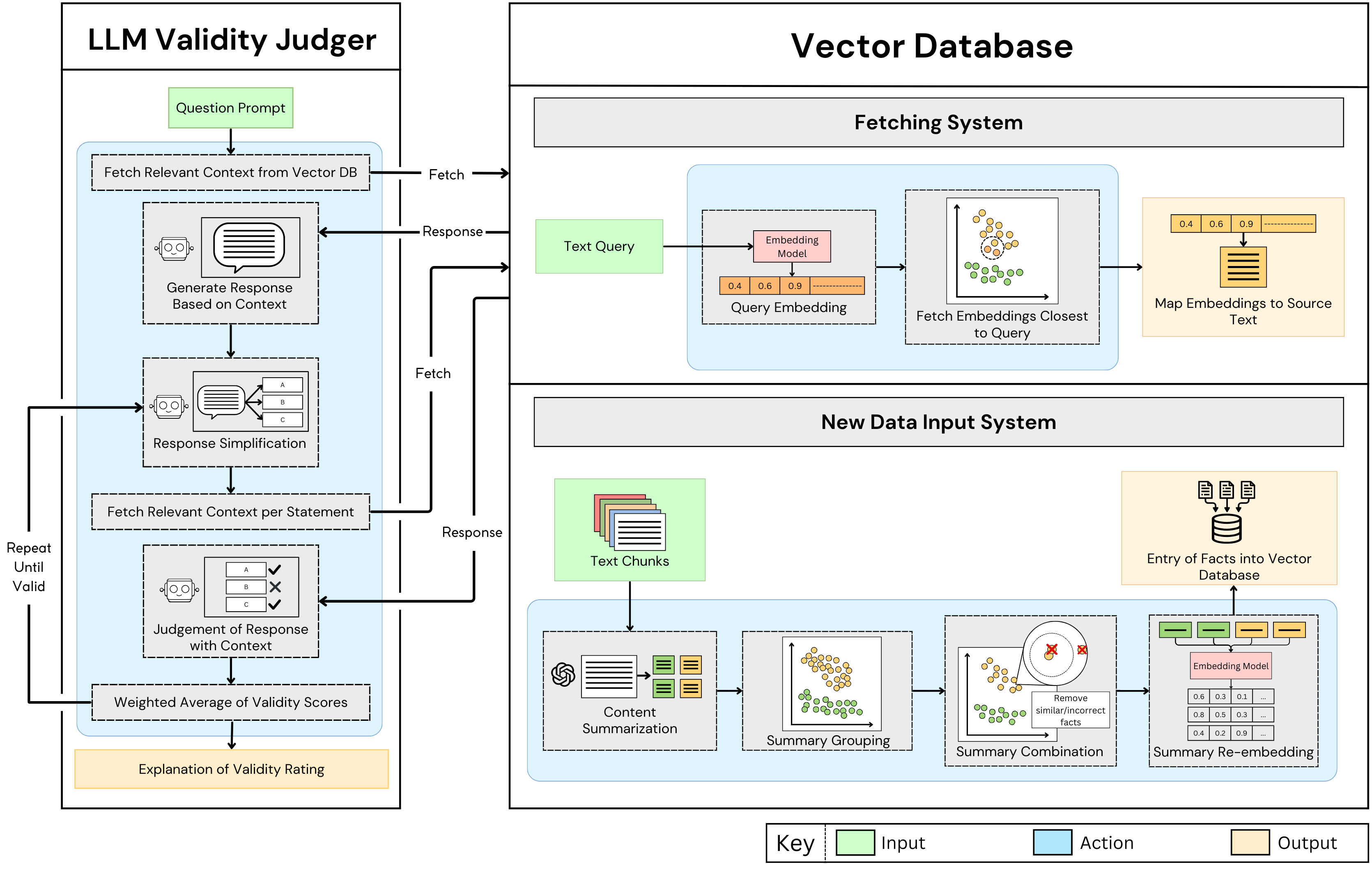
System Architecture
- New Data Input System: Fact Extraction and Storage
- Input: Multiple text chunks containing factual information.
- Output: Extracted facts embedded as vector representations, stored in a vector database.
- LLM Validity Judger: Prompt and Response Validation
- Input: A GPT prompt and its corresponding response.
- Output: An overall validity rating between 0 and 1 indicating the accuracy of the prompt/response pair, along with optional reasoning.
Implementation Details
New Data Input System
Fetching Contexts: All contexts are fetched from the PubMedQA dataset to serve as the input data for preprocessing
dataset = load_dataset("qiaojin/PubMedQA", name="pqa_labeled", split="train")
data = dataset.select_columns(["question", "context", "pubid"])
Summarization and Compression: Each context is summarized using GPT-4o-mini, compressing the content into concise paragraphs. This step ensures efficient downstream processing and storage
new_contexts = [
str(x)
for x in await async_gpt_calls(
[get_summarize_prompt(context) for context in raw_contexts]
)
]
Embedding with OpenAI Models: The summarized contexts are embedded into high-dimensional vector representations using OpenAI’s text-embedding-3-large model
result = client.embeddings.create(
input=text,
model="text-embedding-3-large",
)
return EmbeddingResponse(
result.data[0].embedding,
result.model,
result.usage,
)
Clustering with DBSCAN: The embeddings are grouped into clusters using DBSCAN, which identifies similar contexts without requiring predefined categories. This step is critical for organizing related data efficiently
def cluster(vectors: list[Vector], eps=45.0, min_samples=1) -> list[list[str]]:
data = StandardScaler().fit_transform(
np.array([vector["vector"] for vector in vectors])
)
db = DBSCAN(eps=eps, min_samples=min_samples, metric="euclidean").fit(data)
clusters: dict[str, list[str]] = {}
for item, label in zip(vectors, db.labels_):
clusters.setdefault(label, []).append(item["id"])
return [vectors for label, vectors in clusters.items() if label != -1]
Context Combination and Summarization: Context summaries within each cluster are combined and re-summarized into unified representations using GPT-4o-mini, further reducing redundancy and optimizing coherence
def combine_and_summarize(cluster: list[str]):
combined_context = " ".join(cluster)
return summarize_context(combined_context)
Final Embedding and Storage: The new summaries are re-embedded with text-embedding-3-large
vectors = [
{"id": id, "values": embedding.vector, "metadata": {"content": content}}
for id, embedding, content in zip(ids, embeddings, contexts)
]
index.upsert(vectors=vectors, namespace="pubmed_summarized")
LLM Validity Judger
Decomposing Responses: GPT processes the prompt and its corresponding response, breaking them into discrete factual statements. Each statement is assigned an importance score (0–1), indicating its relevance to the prompt.
def decompose_response(response: str) -> list[dict]:
sentences = response.split(".")
return [{"statement": s.strip(), "importance": 0.5} for s in sentences if s.strip()]
Proximity Search: For each statement, the system retrieves nearby facts from the vector database through a semantic proximity search
def proximity_search(statement_embedding, top_k=5):
response = index.query(vector=statement_embedding, top_k=top_k)
return response.matches
Validity Scoring: Each statement is evaluated against its contextual facts using GPT, which assigns a validity score between 0 and 1 based on alignment. This evaluation determines how well the statement aligns with retrieved facts
def evaluate_validity(statement: str, context: str):
prompt = f"Evaluate: '{statement}' based on: '{context}'. Assign a validity score (0-1)."
response = client.chat.completions.create(model="gpt-4o-mini", prompt=prompt, max_tokens=10)
return float(response.choices[0].text.strip())
Weighted Average Calculation: The validity scores are aggregated into a weighted average, where the weights are derived from the importance scores of the statements. This weighted score represents the overall factual accuracy of the response.
def calculate_weighted_average(scores: list[float], weights: list[float]):
return sum(s * w for s, w in zip(scores, weights)) / sum(weights)
Explainability: If required, GPT generates a rationale for the validity rating, outlining which facts were used, how alignment was determined, and any potential conflicts. This reasoning enhances interpretability and transparency.
def generate_explanation(statement: str, context: str):
prompt = f"Explain validity of: '{statement}' in context: '{context}'"
response = client.chat.completions.create(model="gpt-4o-mini", prompt=prompt, max_tokens=150)
return response.choices[0].text.strip()
Advantages of This System
The proposed system introduces several features that enhance the reliability and adaptability of existing RAG pipelines:
-
Innovative Design: By integrating techniques like LLM summarization, DBSCAN clustering, and vectorized fact storage, the system introduces a new framework for precise fact validation and efficient data storage reduction.
-
Streamlined Architecture: The system’s design supports simple integration with existing RAG systems while reducing storage needs and retrieval token usage. This adaptability ensures suitability and long-term applicability for large-scale applications across various domains.
-
Granular Fact Verification: By decomposing responses into discrete factual units and validating each against a vectorized knowledge base, the system achieves significantly higher precision compared to traditional document- or paragraph-level validation methods, reducing inaccuracies and improving trustworthiness.
Why Not KNN for Clustering?
K-nearest neighbor (KNN) was considered for fact clustering but was ultimately not used due to its reliance on predefined parameters, such as the number of clusters or neighbors—constraints that are impractical for real-world datasets with high diversity
Additional Note
If the dataset is preprocessed to isolate one specific fact per entry, we recommend bypassing that step. Instead, the data can directly enter our model, which dynamically groups related facts. This approach preserves the richness of the dataset and streamlines the overall workflow.
Experimentation and Results
We evaluated our proposed pipeline by benchmarking it against a Traditional Retrieval-Augmented Generation (RAG) Pipeline using the PubMedQA dataset
Traditional RAG Pipeline
The traditional RAG pipeline was tested under ideal conditions, embedding and retrieving the labeled contexts directly from the PubMedQA dataset
The traditional pipeline workflow includes the following steps:
- Embed each context using OpenAI’s
text-embedding-3-largemodel. - Store the embeddings in PineconeDB for retrieval.
Comparative Metrics
| Metric | Traditional Pipeline | Proposed Pipeline | Difference |
|---|---|---|---|
| Factual Accuracy | 71.7% | 71.2% | -0.5% |
| RAG Effectiveness | 99.2% | 98.9% | -0.3% |
| Storage Efficiency | 1,351 KB | 571 KB | -57.7% (Reduction) |
Table 1. Comparison of factual accuracy, RAG effectiveness, and storage efficiency between the traditional pipeline and the proposed pipeline. The proposed pipeline achieves comparable performance in accuracy and effectiveness while significantly reducing storage requirements by 57.7%.
Factual Accuracy
We tested factual accuracy to measure how well the system addressed prompts by integrating all processes, including context retrieval, summarization, and LLM response generation. Using the PubMedQA dataset with 1,000 labeled context-question-answer groups, we queried each question and deemed responses correct if they matched the dataset’s answer (yes, no, or maybe)
RAG Effectiveness
RAG effectiveness was evaluated to determine how well each pipeline retrieved the most relevant context for a given query. The PubMedQA dataset contexts were queried using labeled questions, and a retrieval was marked correct if the top result matched the labeled correct context
Storage Efficiency
We measured storage efficiency by calculating the total size of stored contexts in the vector database (excluding vector embeddings). The traditional pipeline required 1,351 KB, whereas our pipeline used only 571 KB, a reduction of 57.7%. This demonstrates the significant compression achieved through summarization and clustering. The benefits are particularly pronounced in unstructured datasets, where redundant data can be consolidated. While PubMedQA is a structured dataset, in more diverse real-world datasets, the proposed pipeline would likely achieve even greater storage savings. This reduced footprint allows for the storage of larger datasets and faster query times, providing scalability without sacrificing usability.
Validity Judgment with Chain of Thought
In addition to the metrics discussed above, we evaluated the integration of a validity judgment mechanism in both the traditional and proposed pipelines. The PubMedQA dataset, designed for direct question-answer accuracy, presents inherent limitations for chain-of-thought reasoning
When integrated into the proposed pipeline, the accuracy decreased to 68.9%, showcasing areas for refinement in our system rather than inherent shortcomings in the validity judger. This drop is attributed to two primary reasons:
- Skewed Scoring Distribution: Validity and importance scores were overly concentrated near 1, limiting their ability to distinguish subtle differences in factual accuracy.
- Excessive Context Retrieval: The RAG system retrieved more context than necessary, introducing noise to the validation process.
While the PubMedQA dataset is not well-suited for chain-of-thought reasoning, the validity judger still demonstrated its capability to decompose LLM responses into granular statements and retrieve relevant contexts for validation. These findings demonstrate its potential as a strong component for factual validation, particularly on tasks requiring multi-step reasoning. Addressing scoring and retrieval challenges, along with testing on more reasoning-intensive datasets, will likely see significant improvements in both accuracy and efficiency.
Alternative Solution: Statement Extraction
One of the main limitations of the proposed framework (summarization-based) is the potential loss of important contextual details—particularly concerning in high-stakes domains such as finance, law, or medicine. To mitigate this risk and retain comprehensive coverage of critical information, we introduce an Alternative Pipeline that avoids excessive compression by converting the input data into standalone, verifiable statements. When an input passage can’t safely be condensed, the system simply reproduces statements identical to the source text, thus ensuring no crucial content is omitted. Rather than aiming for a prescribed compression metric, the pipeline focuses on statement-level extraction, preserving essential facts while eliminating redundancies and inaccuracies.
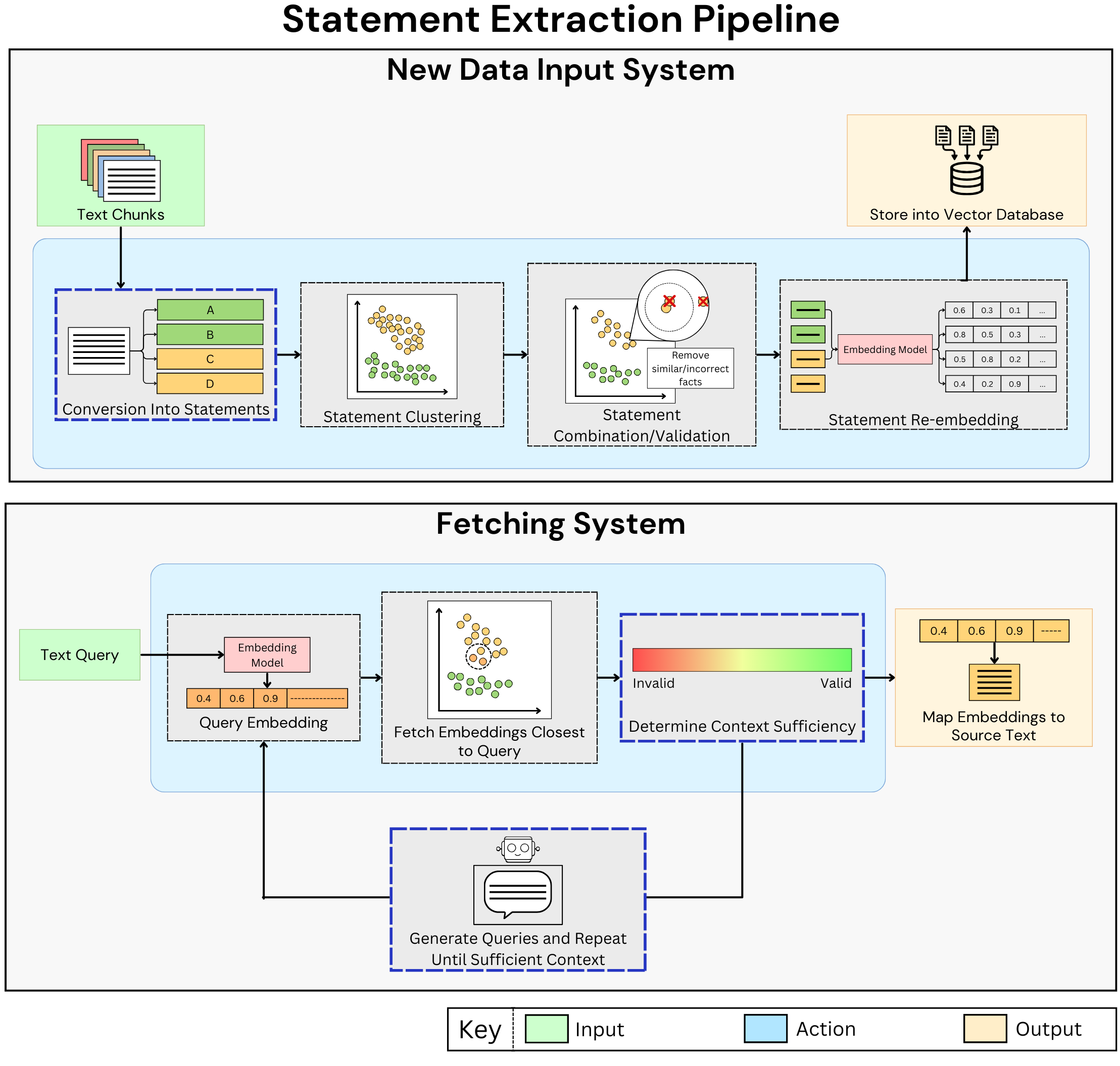
Extended Benchmarks
To evaluate this alternative pipeline, experiments were conducted on two widely used QA datasets: Stanford Question Answering Dataset (SQuAD)
SQuAD
| Metric | Traditional Pipeline | Statement Extraction | Difference |
|---|---|---|---|
| Factual Accuracy | 87.3% | 89.7% | +2.4% |
| Storage Size | 1.4 MB | 1.1 MB | -21.43% |
Table 2. On the SQuAD dataset, statement extraction yields a 2.4% increase in factual accuracy while reducing storage size by 21.43%.
HotpotQA
| Metric | Traditional Pipeline | Statement Extraction | Difference |
|---|---|---|---|
| Factual Accuracy | 92.0% | 93.3% | +1.3% |
| Storage Size | 763 KB | 701 KB | -8.12% |
Table 3. On the HotpotQA dataset, the statement extraction pipeline achieves a 1.3% higher accuracy while reducing storage by 8.12%. Though less significant than SQuAD, the improvement demonstrates that statement-level coverage can enhance reliability even in multi-hop question answering tasks.
Notably, in comparison to our proposed pipeline, the storage savings here are not as large. However, this Alternative Pipeline ensures no critical details are inadvertently removed. Just as with the proposed approach, it integrates easily into existing RAG setups, requiring minimal computational overhead. DBSCAN and cosine similarity are relatively lightweight, and the LLM calls typically cost only around $0.01 per API call.
Realistic Usage
Most real-world data comes from unstructured sources, including blog posts, news reports, or technical articles. Below, we demonstrate a small-scale test with two AI-related news articles—one from Google DeepMind
| Metric | Google Deepmind | Wired Article | Combination |
|---|---|---|---|
| Raw Size | 3.0 KB | 5.4 KB | 8.4 KB |
| Statement Extraction Size | 2.2 KB | 2.3 KB | 3.3 KB |
| Percentage Reduction | 26.67% | 57.41% | 60.71% |
Table 4. Storage sizes before and after statement extraction. Combining both articles after statement extraction yields a 3.3 KB storage size, significantly smaller than the raw 8.4 KB.
Through DBSCAN clustering, near-duplicate statements—such as multiple introductions of “Gemini 2.0” from different perspectives—are merged into a single statement without risking the loss of important data. In high-stakes settings, this pipeline can similarly maintain critical details (e.g., disclaimers, side effects, or legal clauses). Consequently, while it may not compress as aggressively as the proposed pipeline, the Alternative Pipeline provides stronger guarantees of context sensitivity and factual completeness.
Broader Implications
The results of these two pipelines highlight their potential to improve how RAG systems handle unstructured and large-scale datasets. By either compressing data via summarization or preserving complete details through statement extraction, it expands the capacity of vector databases, allowing systems to manage larger and more diverse datasets without sacrificing query performance. Such scalability is critical for real-world applications and for increasing context windows, enabling more complex multi-step reasoning tasks and better contextual understanding
Furthermore, by leveraging modular components like clustering and vectorized storage, it enables future systems to integrate real-time updates, ensuring that models stay relevant as knowledge evolves without requiring full retraining. The design also ensures seamless integration with existing RAG and GPT systems, supporting easy implementation while allowing for domain-specific customization. As a result, organizations and researchers can tailor these methods to build specialized QA systems, bias detection tools, or other applications where data quality is essential.
Limitations and Future Work
- Suboptimal Fit:
- The data retrieved may not always align perfectly with the prompt, leading to potential mismatches in utility.
- Mitigation: Introduce additional retrieval steps that identify and remove irrelevant facts, guided by LLM evaluations.
- Context Relevancy:
- Statements sometimes refer to their original context, making them unhelpful when used by themselves.
- Mitigation: Better prompt engineering for statement generation or additional agents to ensure statements are standalone before entry into the database.
- Potential Source Bias:
- Bias in the original source documents can propagate into the system, affecting the impartiality of responses.
- Mitigation: Increase the number of trusted source documents to prevent bias by having a higher quantity of unbiased statements overrule the lower quantity of biased statements.
Future Direction: Concept-Based Fact Representation
Building on the strengths of the current system, a future enhancement could involve representing facts as structured relationships between concepts (e.g., CONCEPT 1, CONNECTION, CONCEPT 2). By storing concepts as Word2Vec embeddings and dynamically mapping their relationships in a database, this approach could enable more granular validation and reasoning
The potential benefits of this approach include:
- Improved Contextual Validation: Exploring relationships between concepts could strengthen the system’s ability to handle complex queries, reducing the risk of context misalignment and improving factual accuracy.
- Enhanced Scalability: Dynamically storing concepts and their connections would allow the system to adapt to new knowledge over time, enhancing long-term usability and robustness.
- Greater Explainability: Converting retrieved connections into human-readable formats could improve transparency, offering clearer and more interpretable rationales for decisions made by the system.
While this concept represents a forward-looking direction, it builds naturally on the goals of the current system. By enhancing scalability, reliability, and transparency, it offers a pathway for advancing the framework in future iterations.
Reproducibility
We have open-sourced all code for our framework at Tonyhrule/Factual-Validation-Simplification. The repository contains complete scripts and instructions for replicating the results from this work. We hope this open-source release facilitates public auditing, broader adoption of our methods, encourages community-driven improvements, and enables new research on trustworthy LLMs.
Conclusion
In this blog post, we explored two approaches to improving the scalability and reliability of RAG pipelines by addressing challenges in storage efficiency and factual accuracy. The first method uses summarization, clustering, and vectorized fact storage to optimize data size while maintaining strong retrieval performance. The second method—the Alternative Pipeline—avoids summarization and instead extracts standalone statements, offering higher fidelity in high-stakes domains where preserving every nuance of context is critical.
Through experimentation with PubMedQA, SQuAD, HotpotQA, the pipelines demonstrated competitive performance relative to traditional methods. The summarization-based pipeline excels in reducing storage space, while statement extraction preserves sensitive details, improving factual accuracy and removing redundant information. Looking ahead, by grounding outputs in verified information and ensuring greater transparency in decision-making, this framework takes a step forward in building trustworthy and explainable AI systems.